01 Introduction
约 419 个字 预计阅读时间 1 分钟
Basic concept¶
Regression(回归):The function outputs a scalar
Classification(分类):Given classes,the function outputs the correct one.
Structured Leraning(结构化学习):create something with structure (image,document)
Model(模型): 带有未知的 Parameter 的 Function
such as :Linner Model:\(y = b + wx_1\)
- feature:已知参数,特性
- \(w (weight)\) and \(b (bias)\) are unknown parameter (leraned from data)
- hyperparameters:超参,自己设定的,such as \(\eta\) (learning rate),sigmoid 数量、batch size。
Loss(损失):Loss is a function of parameters, Loss 值越小越好。such as:\(L(b,w)\)
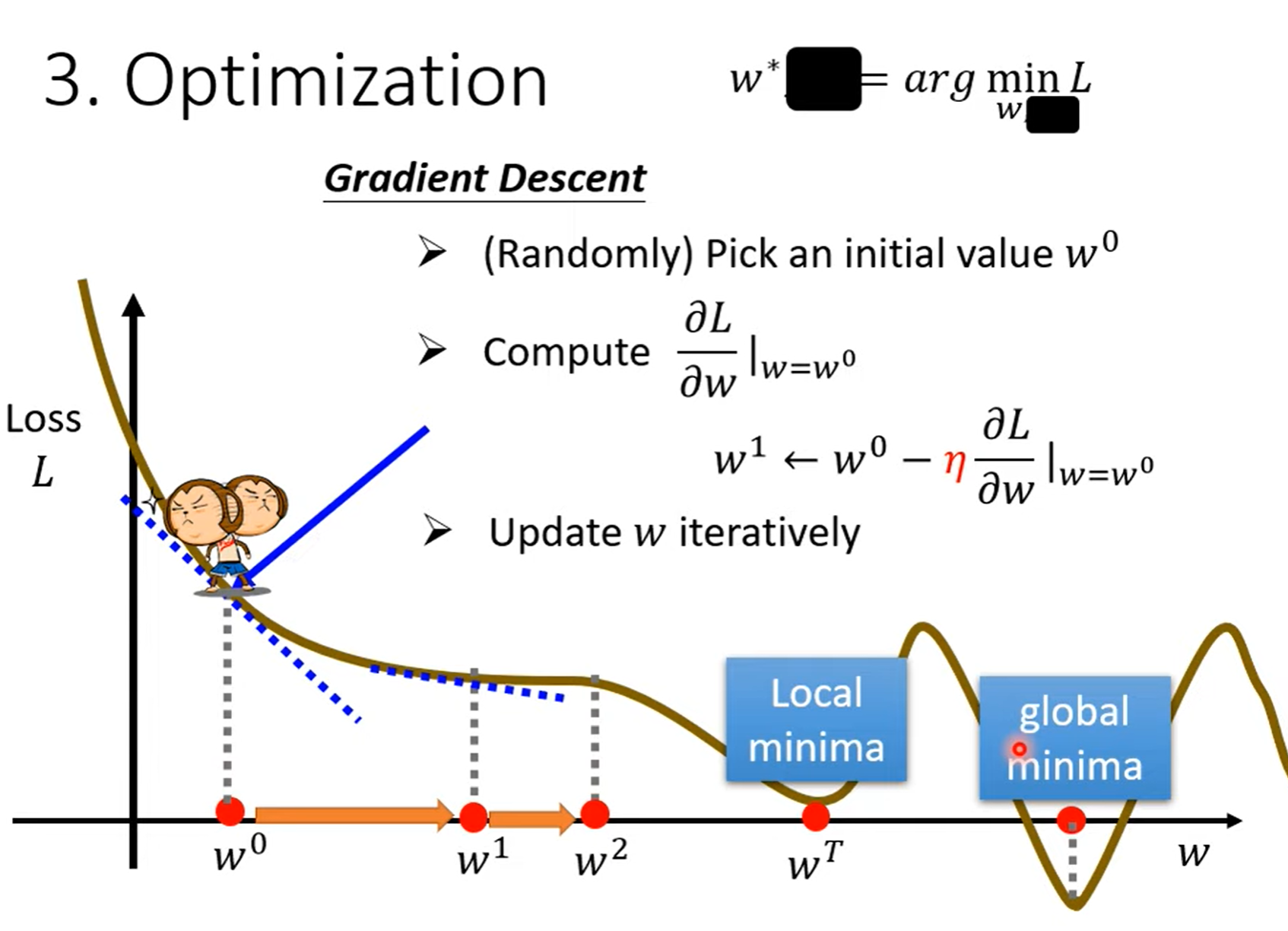
Optimiazation(最优化):such as:Gradient Descent(梯度下降)
Activation Function¶
Sigmod¶
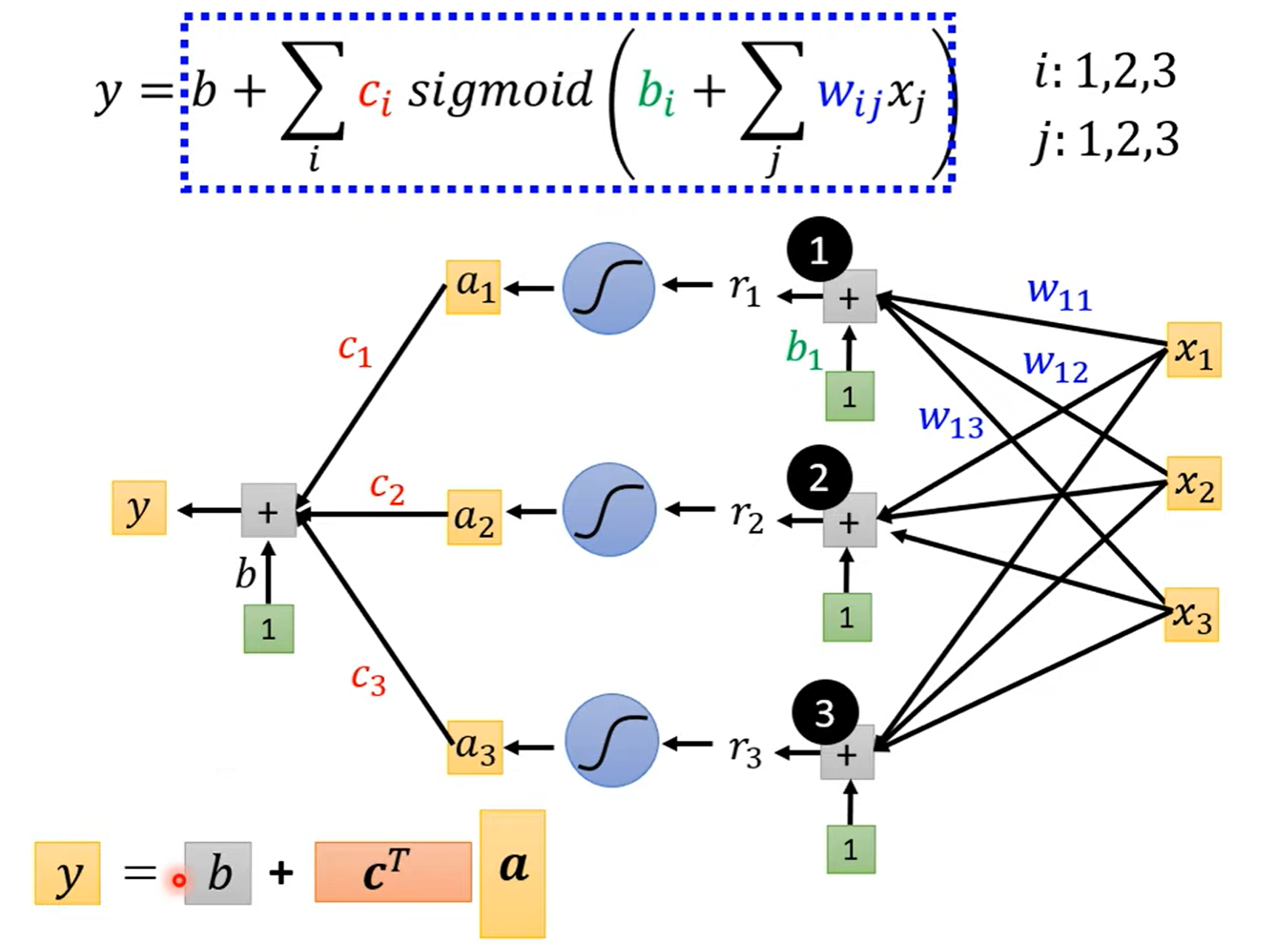
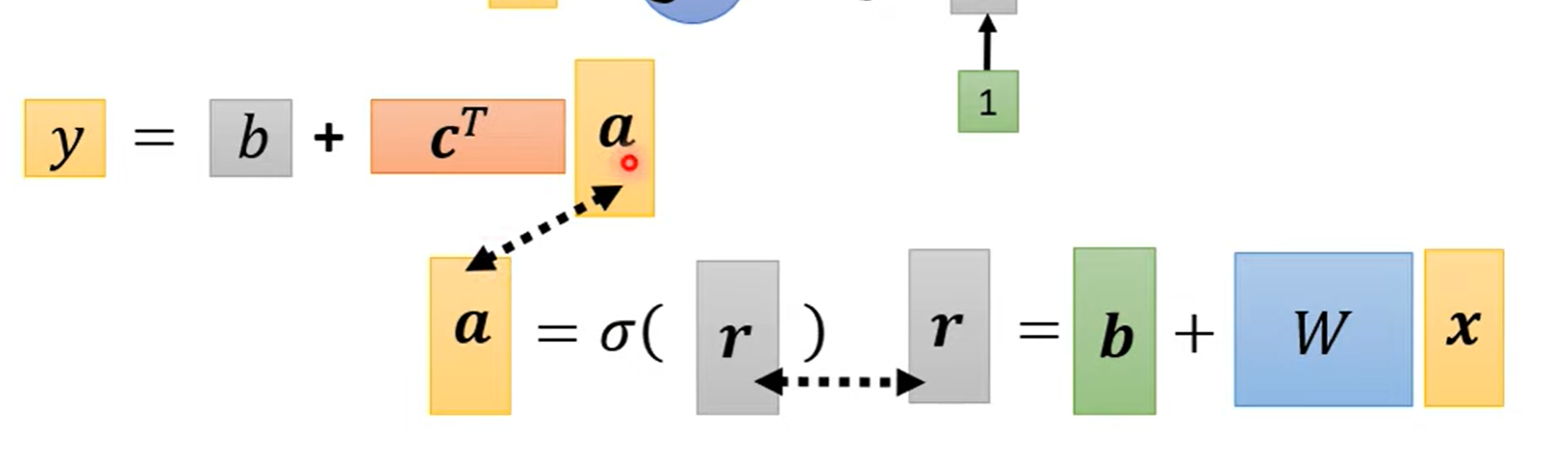
- feature:\(x\)
- Unknown parameters: \(W\) 、 \(b\) and \(c^T\), 统称为 \(\theta\) 。Loss记为 \(L(\theta)\)。
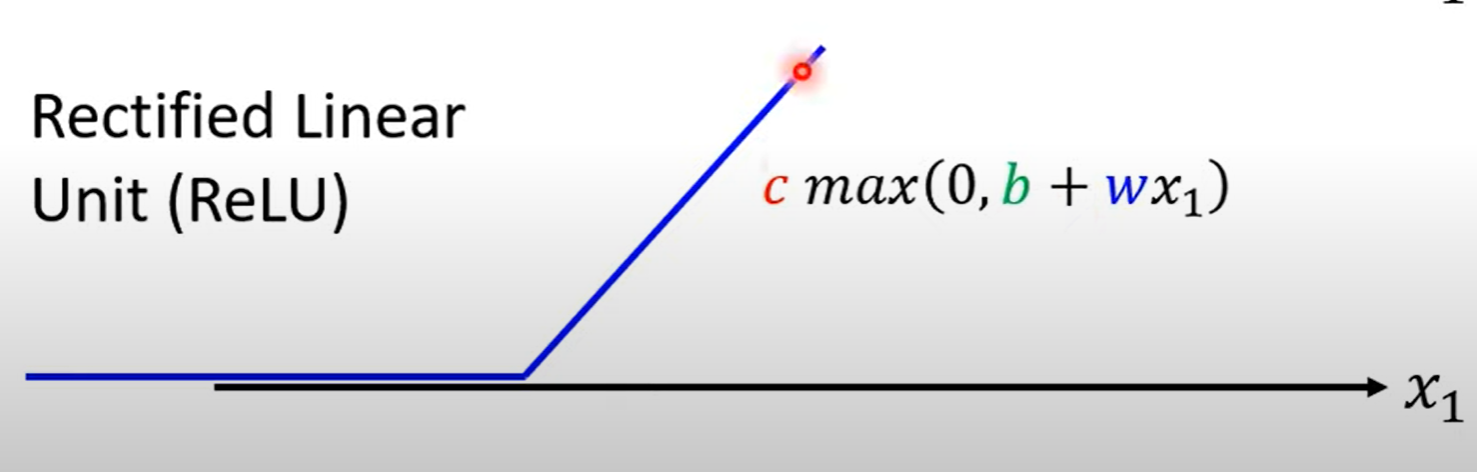
ReLU¶
ReLU(Rectified Linear Uint):
Optimization¶
所有的未知参数都抽象成 \(\theta_i\) ,并将所有 \(\theta\) 放在一起组成一个向量,优化过程就是寻找能使 Loss 最小的 \(\theta\)向量。
将所有的偏微分放在一起组成一个向量 g(梯度),所以更新参数就变成了更新向量了。

过程如下图所示:
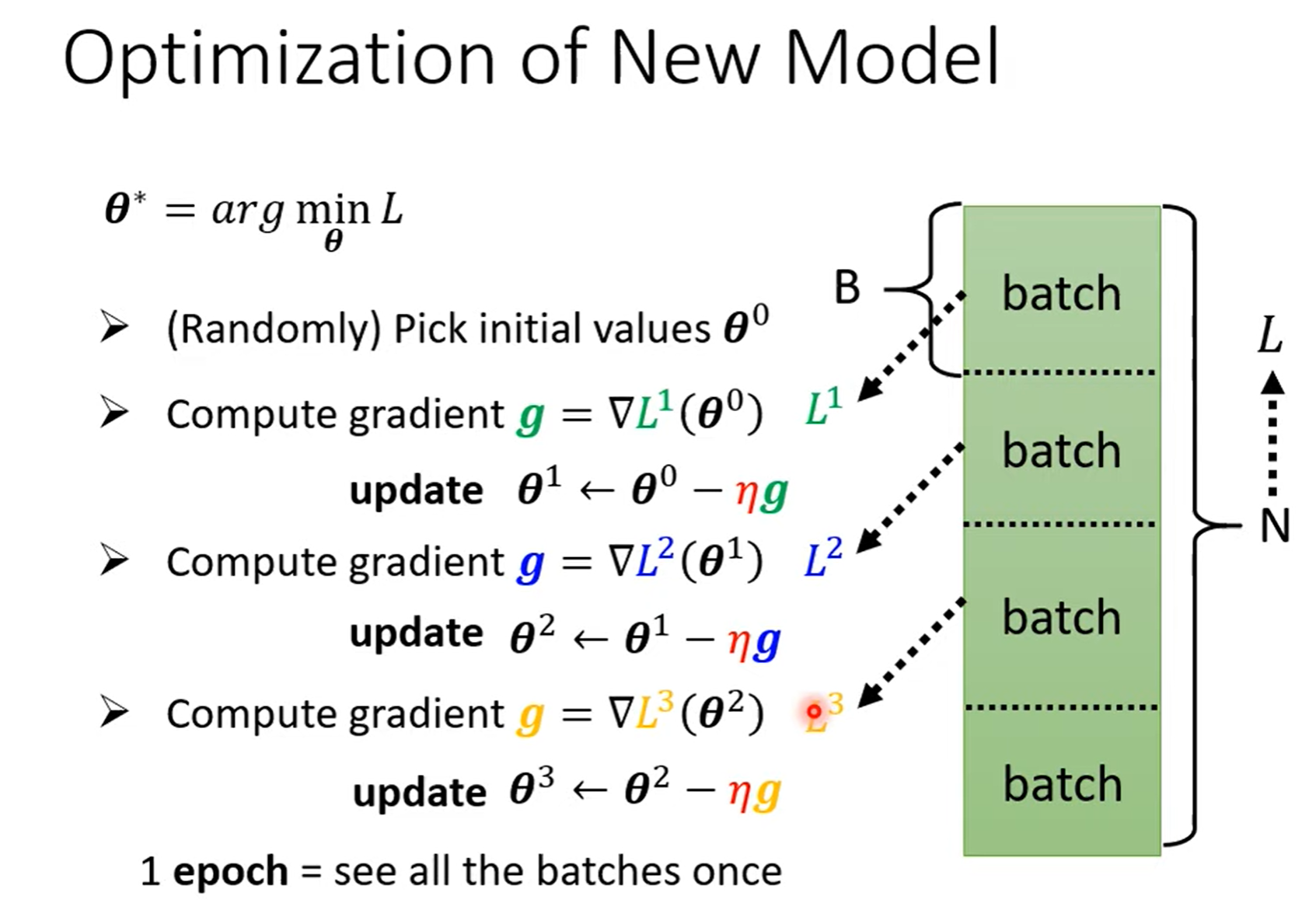
- batch:包/组
- update:更新参数
1 epoch: 所有的 batches 处理一遍
多层神经网络¶
多层神经网络就是先不把激活函数的输出 \(a\) 加在一起,而是再经过多层激活函数之后输出 \(a'\),将 \(a'\) 加在一起作为输出。
每个激活函数(例如sigmoid、ReLU)都是一个 neuron(神经元),每一 hidden layer(隐藏层) 中包含多个神经元。所有的这些东西便组成了 neural network(神经网络)。
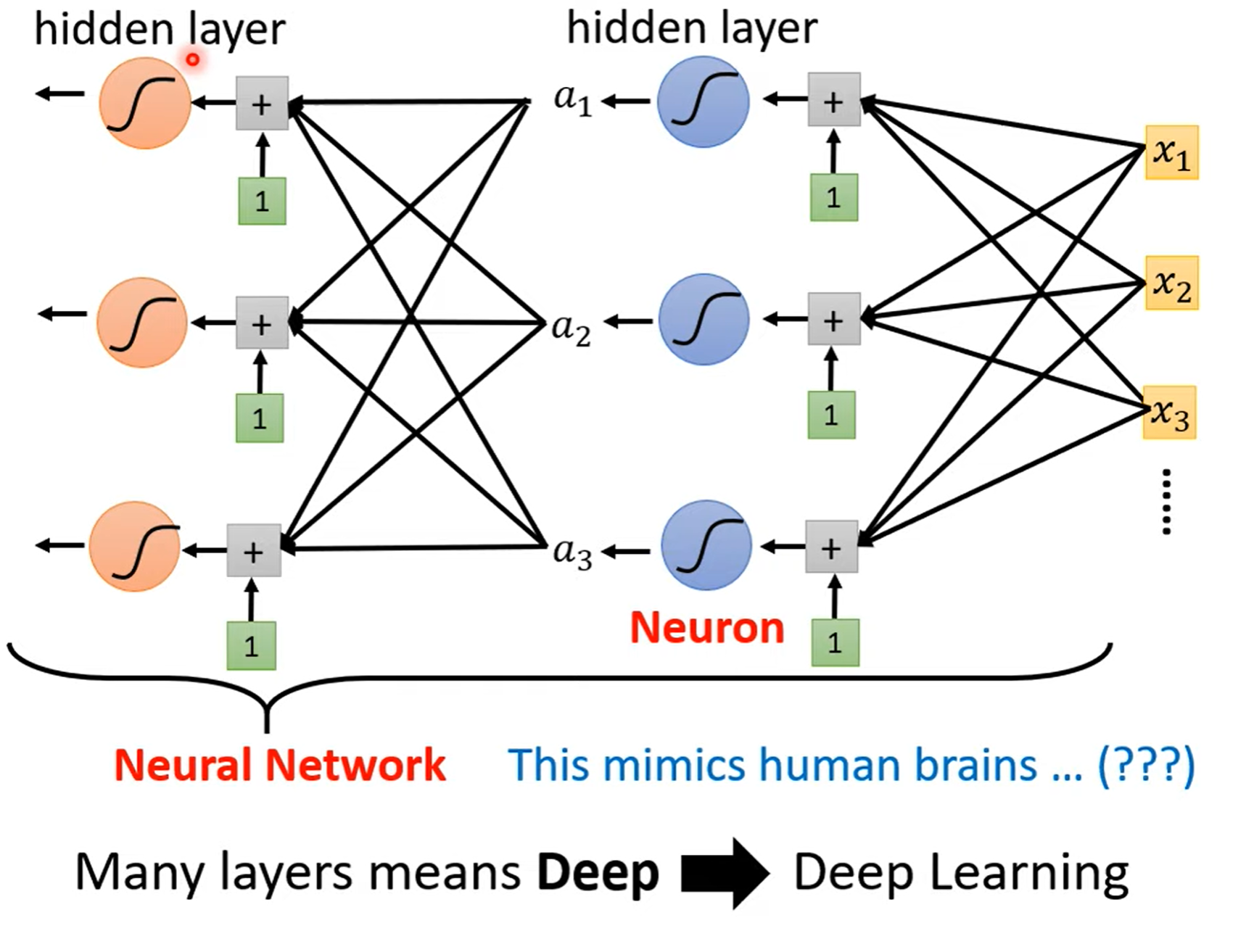
但是隐藏层也不能太多,网络一旦太深,就容易产生 overfitting(过拟合):在训练资料上有很好的表现,但是在测试资料上却表现很差,也就是在实际预测中没卵用!
Created: January 3, 2024