02 Deep Learning
约 1175 个字 预计阅读时间 4 分钟
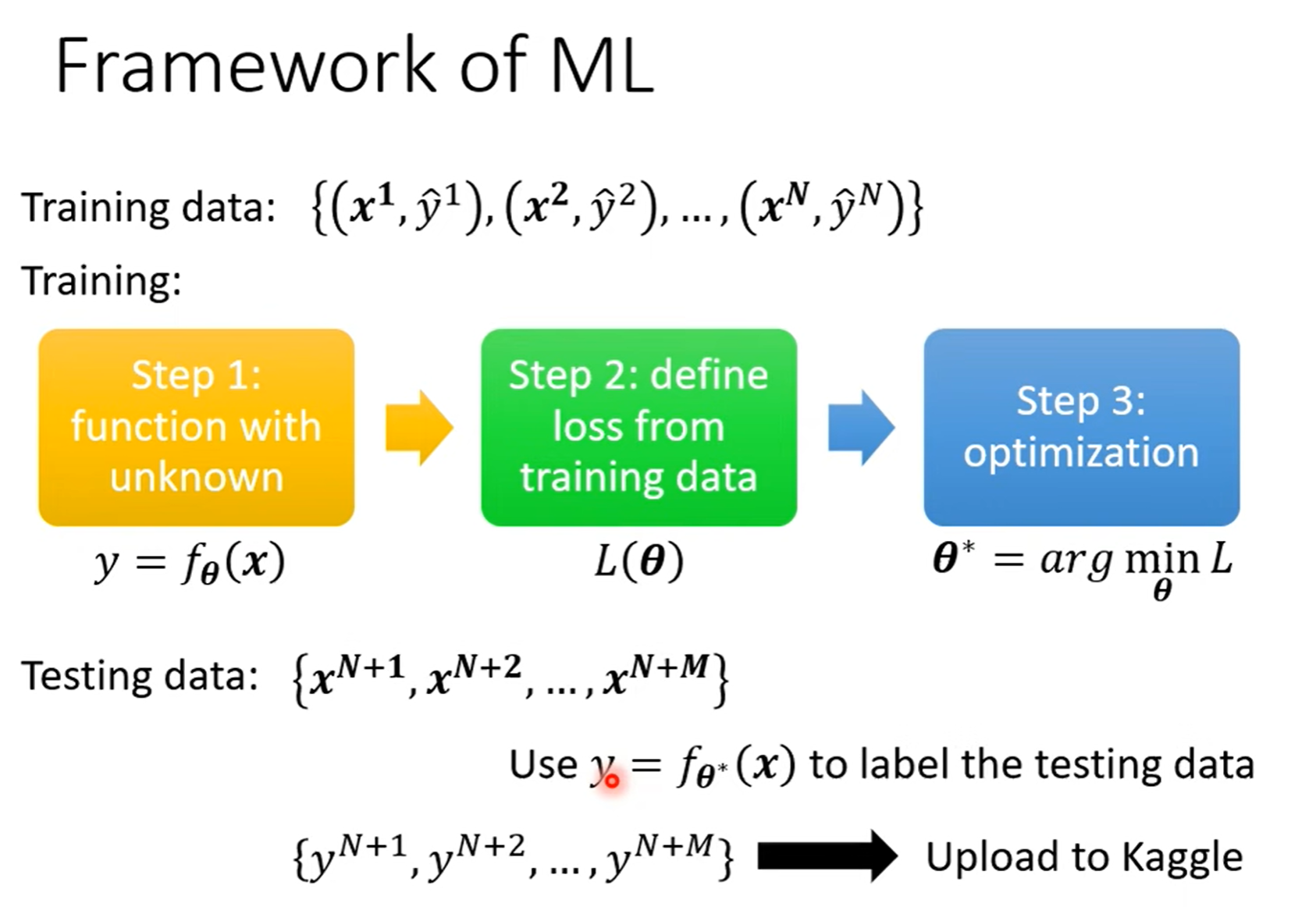
Framework of ML¶
回顾下机器学习的步骤:有一堆含 \(x\) 和 \(\widehat{y}\) 的训练资料,利用这堆训练资料找出能使 loss 最小的参数,再把最佳参数代入猜测的函数 f(x)中,将代入最佳参数的函数用来预测测试资料的 \(y\)(测试资料中只含有 \(x\) )。
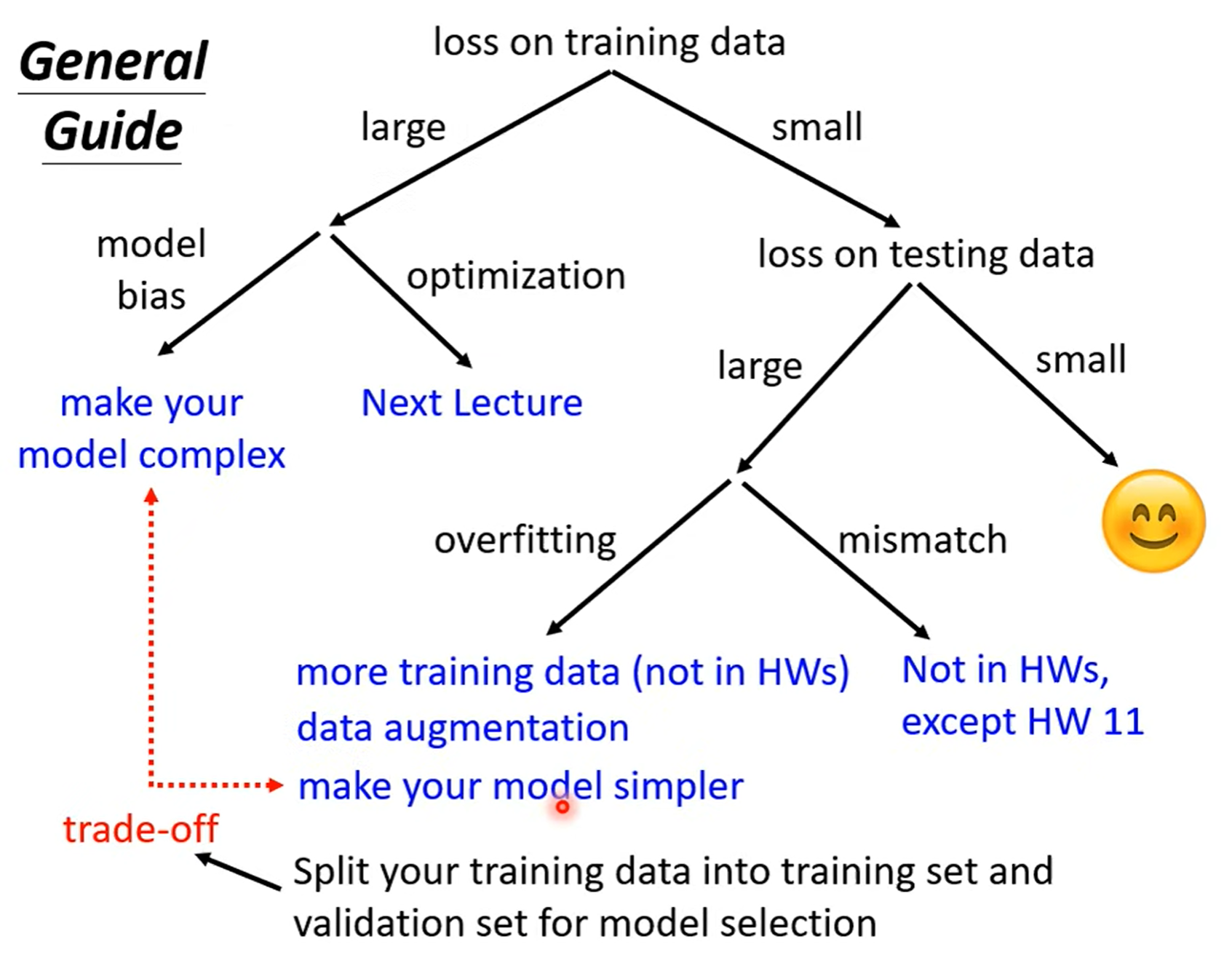
General Guide¶
Loss on training data¶
Model Bias¶
Q: The model is too simple
A: redesign your model to make it more flexible.(使得模型的 弹性/自由度 更大)

Optimization Issue¶
Optimization Issue 是指我们猜测的含未知参数的模型是好的,里面包含能使 loss 更低的可能,但是没有找到使 loss 低的最佳参数。
优化问题就相当于针在海里,可是我们没捞着。最典型的就是 gradient descent 遇到了局部最小值,没有找到能使 loss 很小的参数。
Q:怎么判断优化有没有做好呢?
A:深层的网络没有浅层的 loss 好,具体流程如下
- Gaining the insights from comparison
- Start from shallower networks (or other models), which are easier to optimize
- If deeper networks do not obtain smaller loss on training data,then there is optimization issue.
Loss on testing data¶
Overfitting¶
Overfitting:Small loss on training data,large loss on testing data.
Solution:
- More training data.
- Data augmentation.(创造新资料,但是资料要合理,要根据 domain knowledge 来创造。)
-
decrease model flexibility. (constrained model)
- less parameters
- sharing parameters
- less features
- early stopping
- regularization
- dropout
Trade-off¶
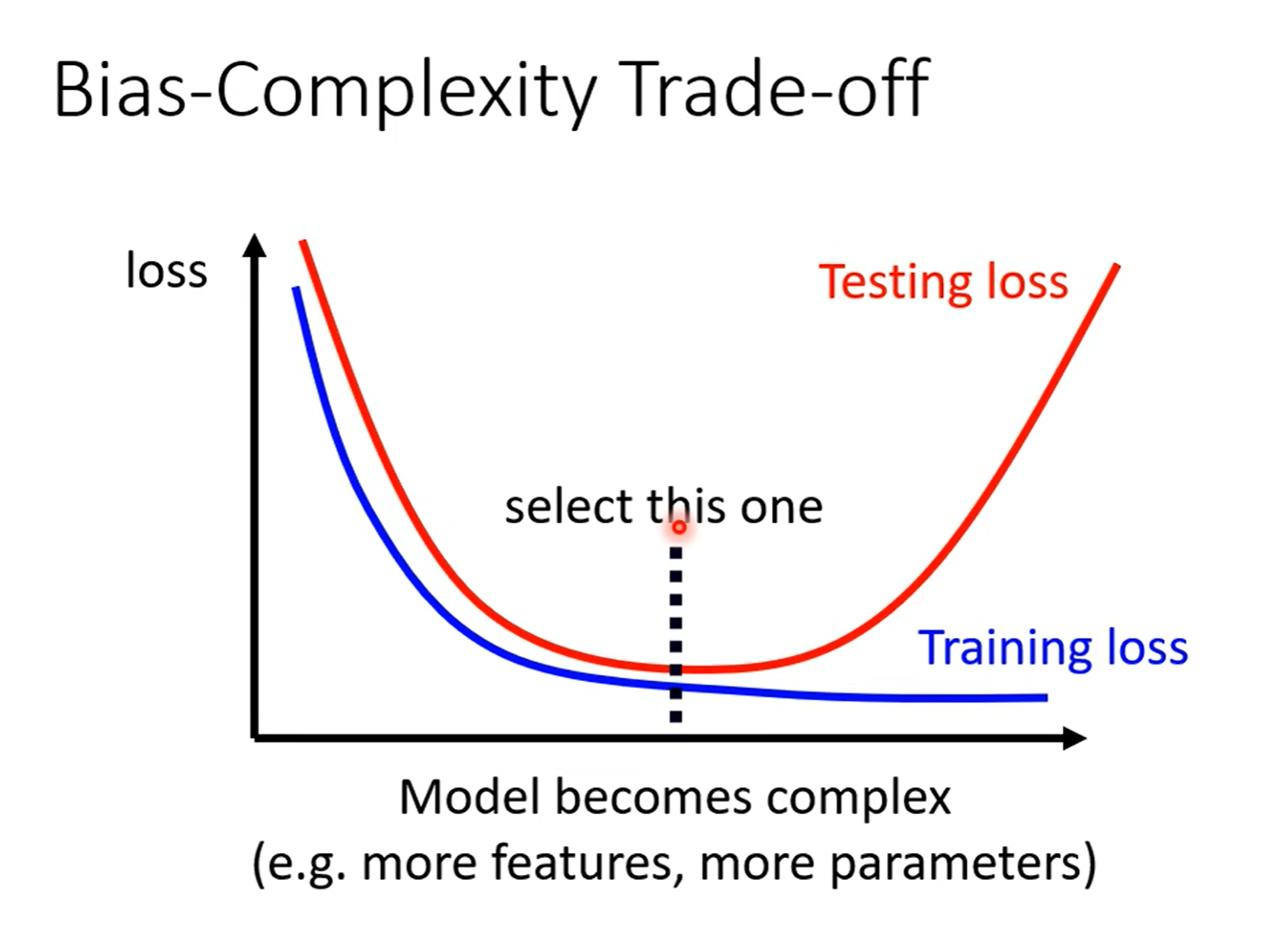
当模型复杂度增加时,training loss是一直降低的,但是 testing loss 是先下降再上升。当复杂度超过下图虚线处,就产生了过拟合,当复杂度远低于虚线处,就产生了 model bias 问题。所以模型复杂度最好是在虚线附近。
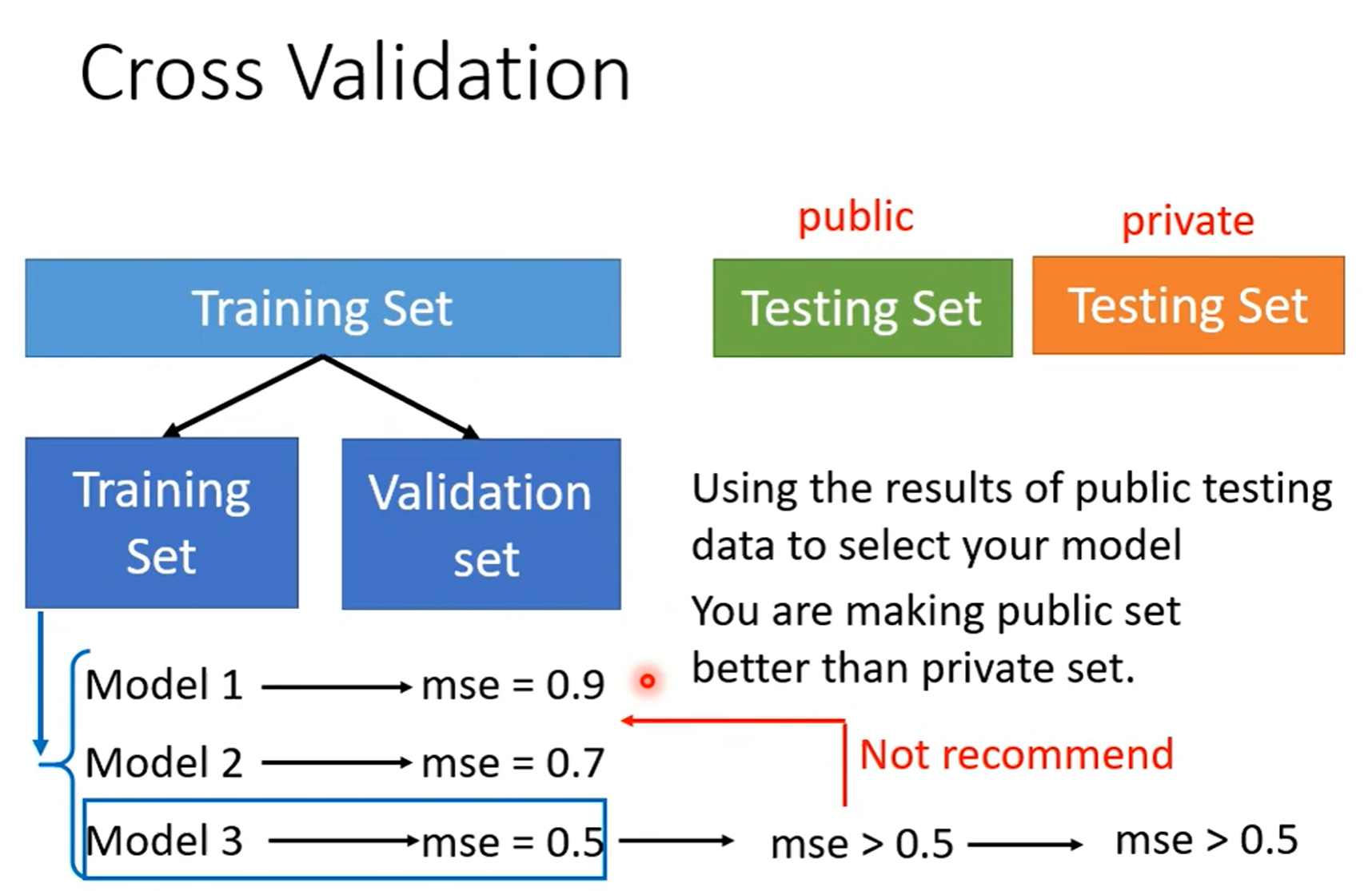
为了让 public testing的资料能代表没看过的真实分布,我们在训练阶段不看 public testing,而 将训练资料中大部分作为训练集,小部分作为验证集(充当了原先public testing的作用)。我们根据验证集的结果去挑模型,这样子public testing 和 private testing的分数就不会差太多,因为两者都能代表真实分布。
mismatch¶
Training and testing data have different distributions.

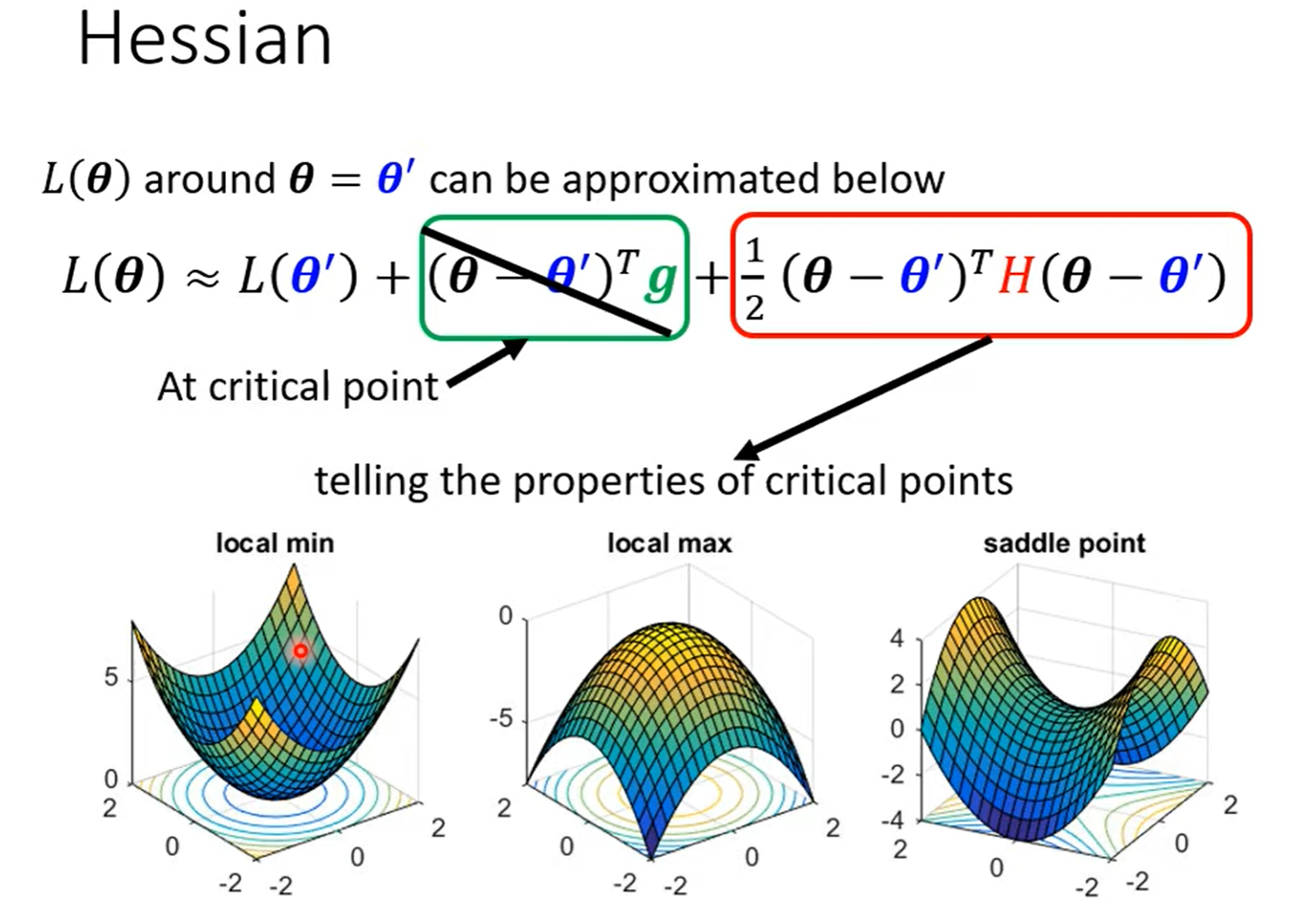
Critical point¶
Critical points have zero gradients.
Critical points can be either saddle points or local minima
- Can be determined by the Hessian matrix
- It is possible to escape saddle points along the direction of eigenvectors(特征向量) of the Hessian matrix.
- Local minima may be rare.
Smaller batch size and momentum help escape critical points.
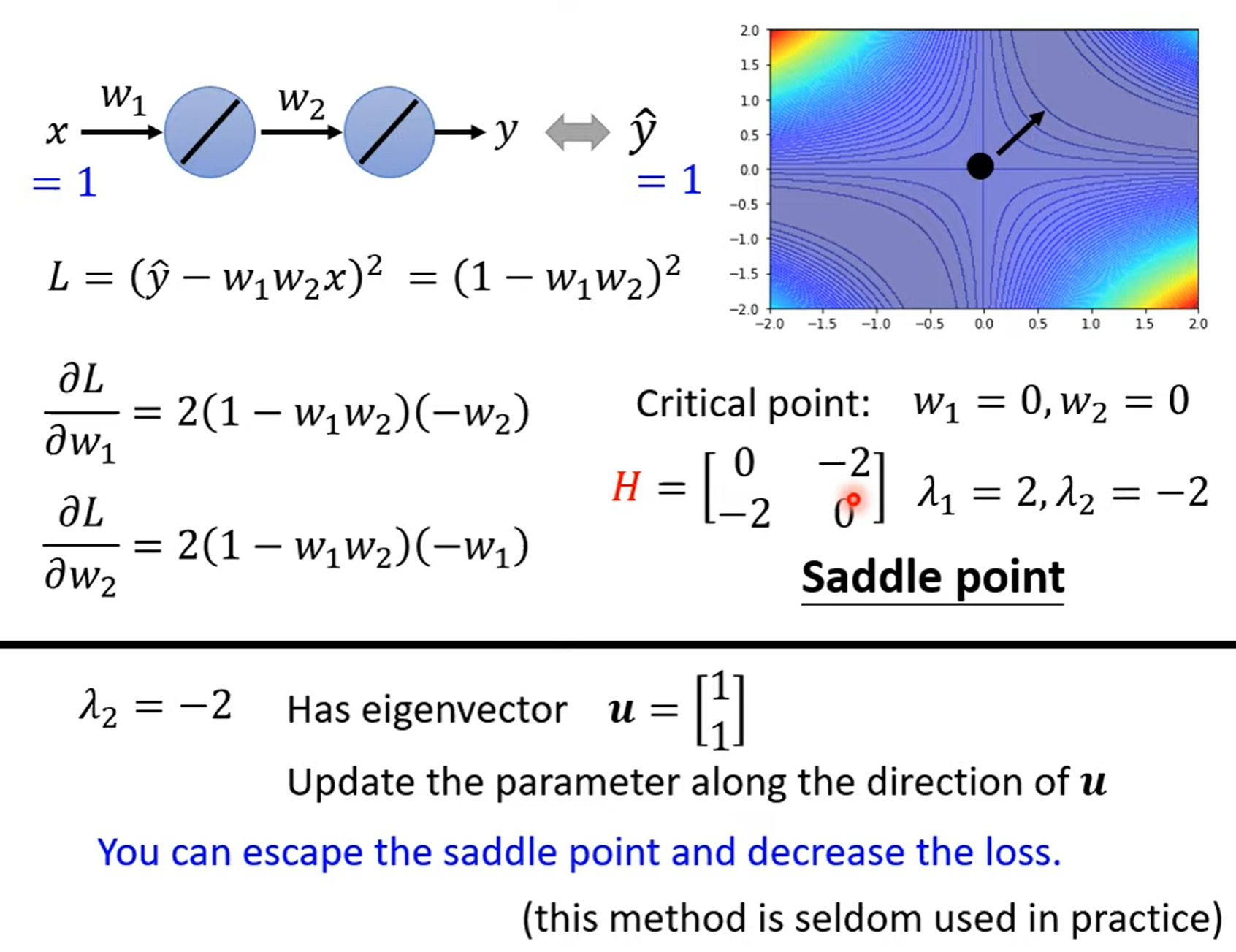
局部最小值(local minima) 和 鞍点(saddle point)
鞍点附近的值既有变大的,也有变小的

saddle point

example
Optimization with Batch¶
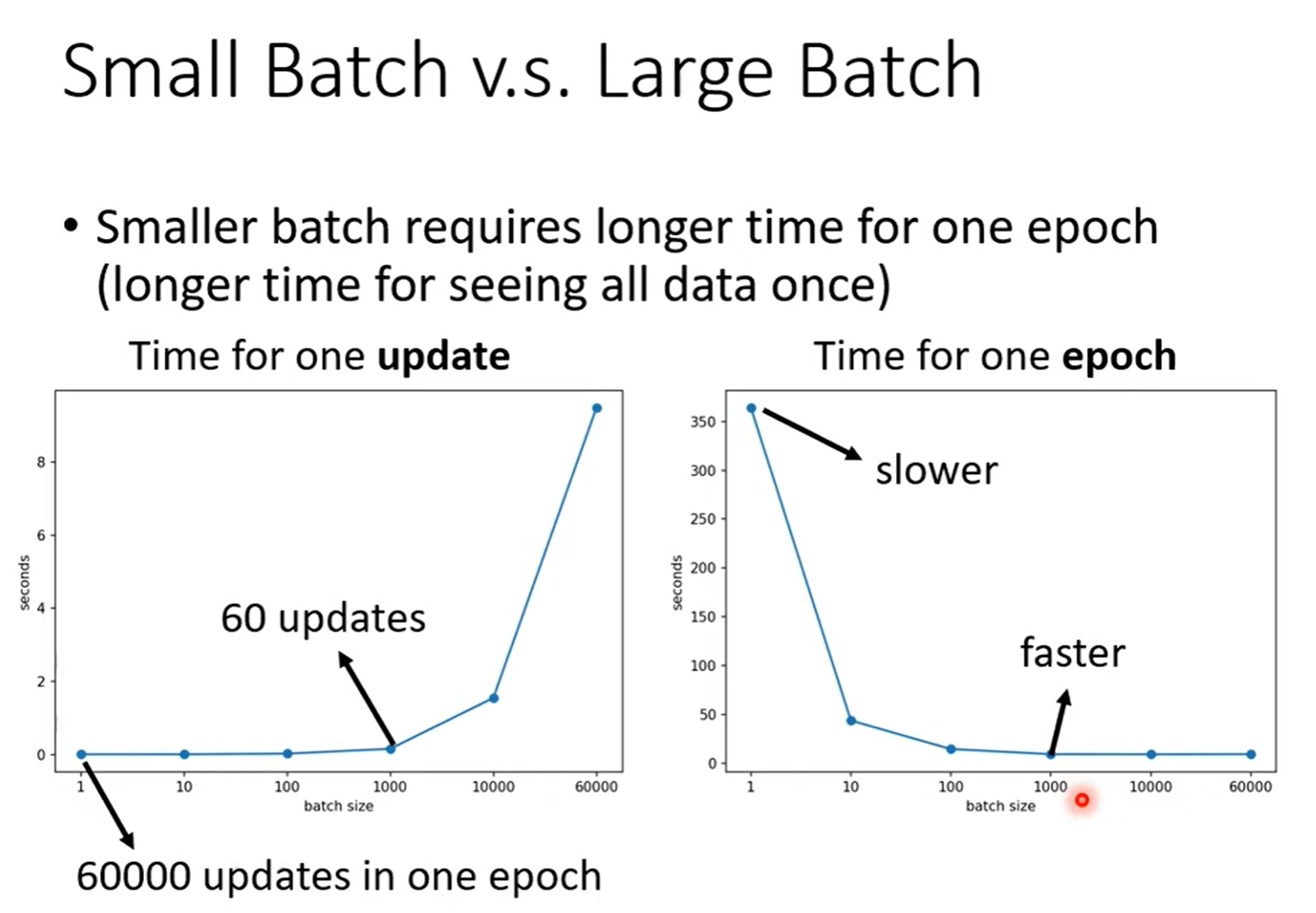
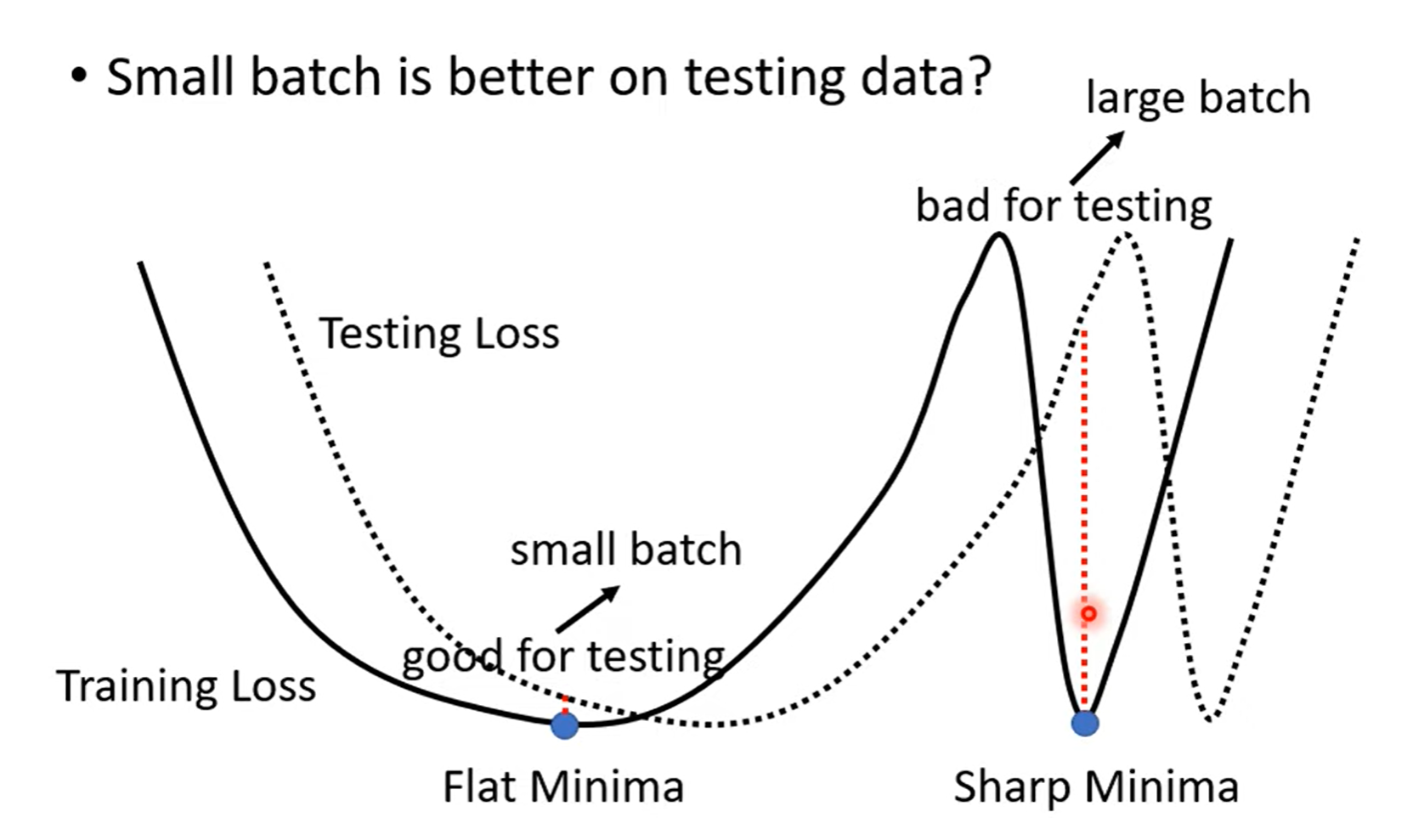
Q: What is wrong with large batch size?
A: Optimization Fails.
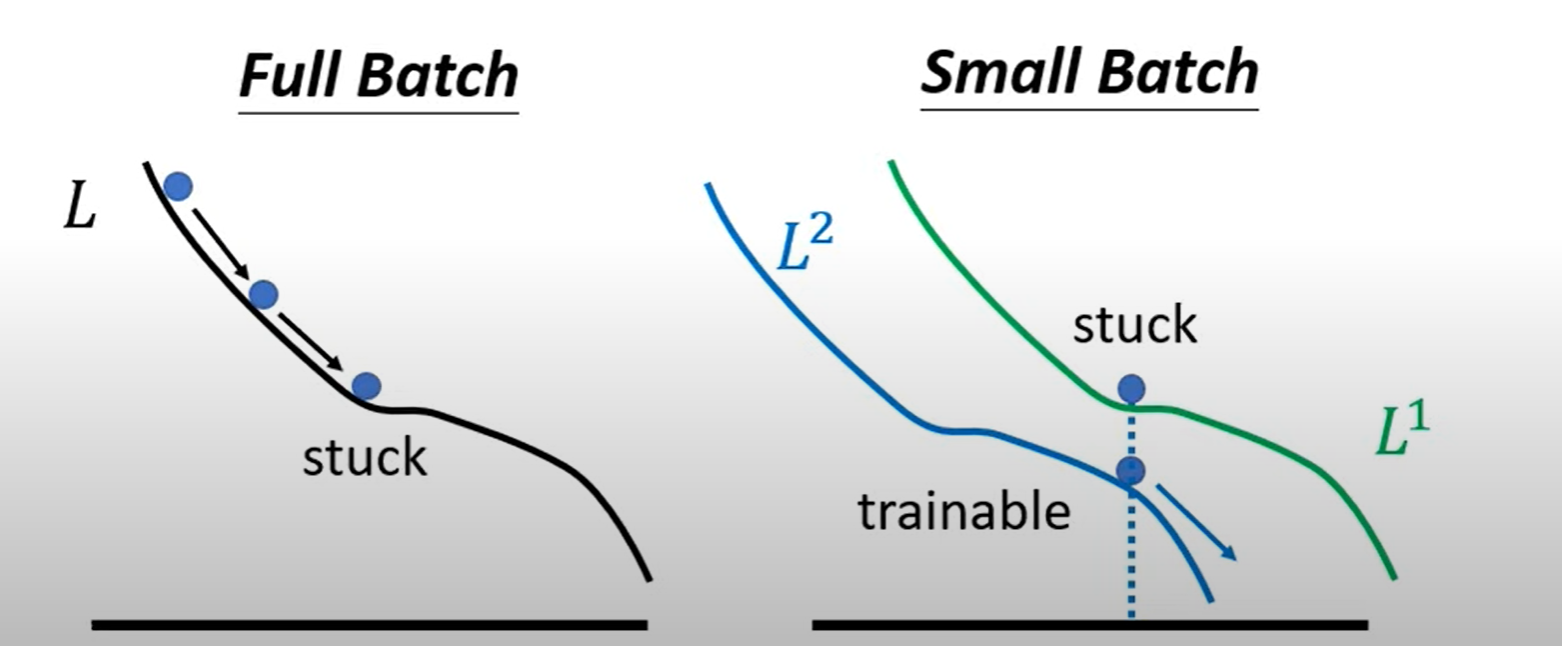
Smaller batch size has better performance
"Noisy" update is better for training,更容易脱离 local minima 的 stuck。
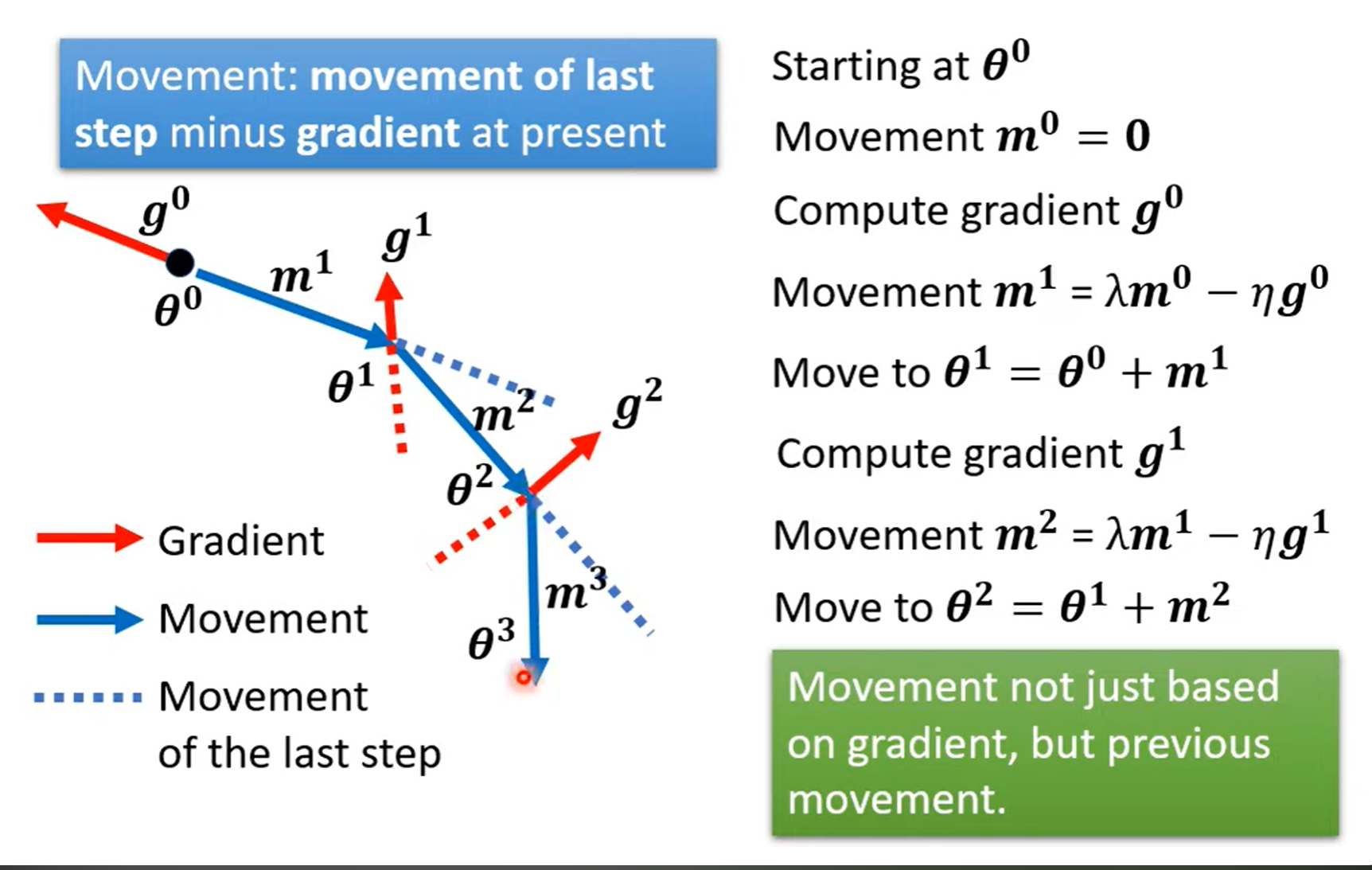
Gradient Decent with Momentum¶
Movement not just based on gradient , but previous movement.
Learning Rate¶
\(\eta\) (Learning Rate)决定 update 的步伐有多大。
在机器学习中,error surface(误差曲面)通常指的是一个函数图像,它描述了模型的损失函数随着模型参数的变化而变化的情况。
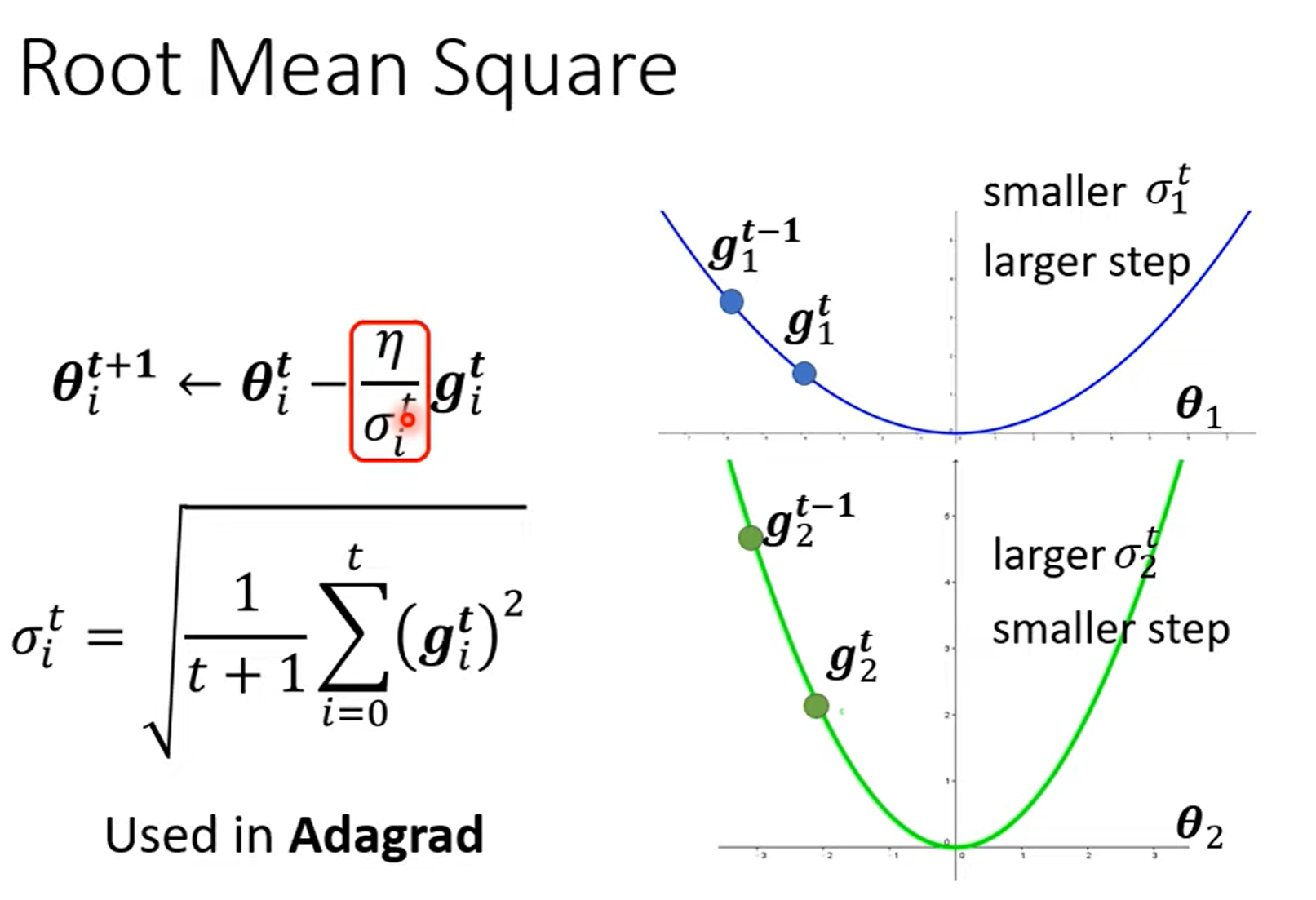
不同的参数采用不同的 learning rate,当参数变化快时,设定小的 learning rate 防止振荡;当参数变化慢时,设定大的 learning rate 加快更新速度。
Root Mean Square¶
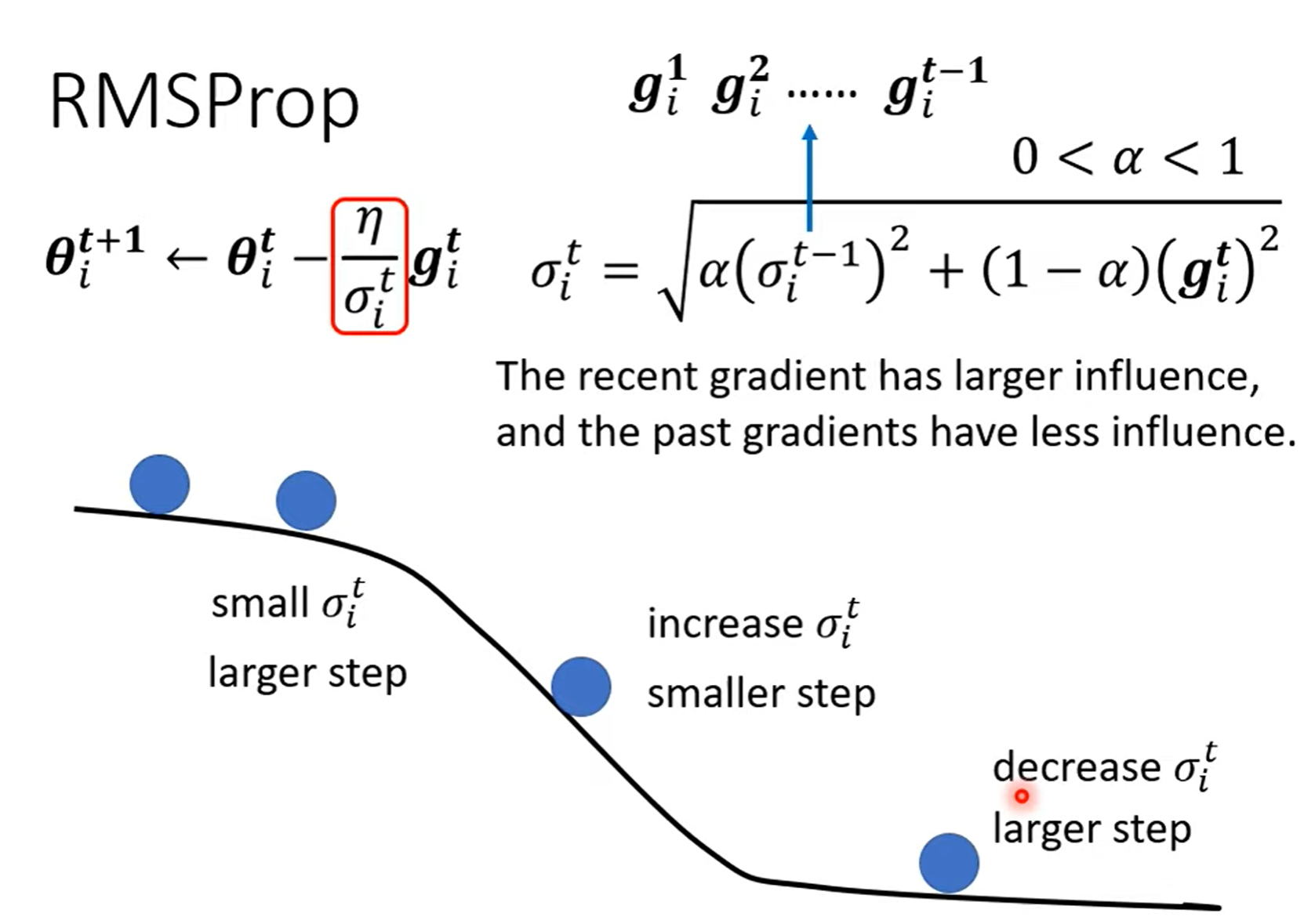
RMSProp¶
不仅考虑到整体的梯度大小,更考虑到梯度的重要性。其中 \(\alpha\) 就是用来决定前一个西伽马和当前 \(g\) 的重要性,上一个西伽马代表过去整体梯度,当前 \(g\) 代表当前位置的坡度缓急。
\(\alpha\) 也是一个 hyperparameters.
Adam¶
Adam = RMSProp + Momentum
Learning Rate Scheduling¶
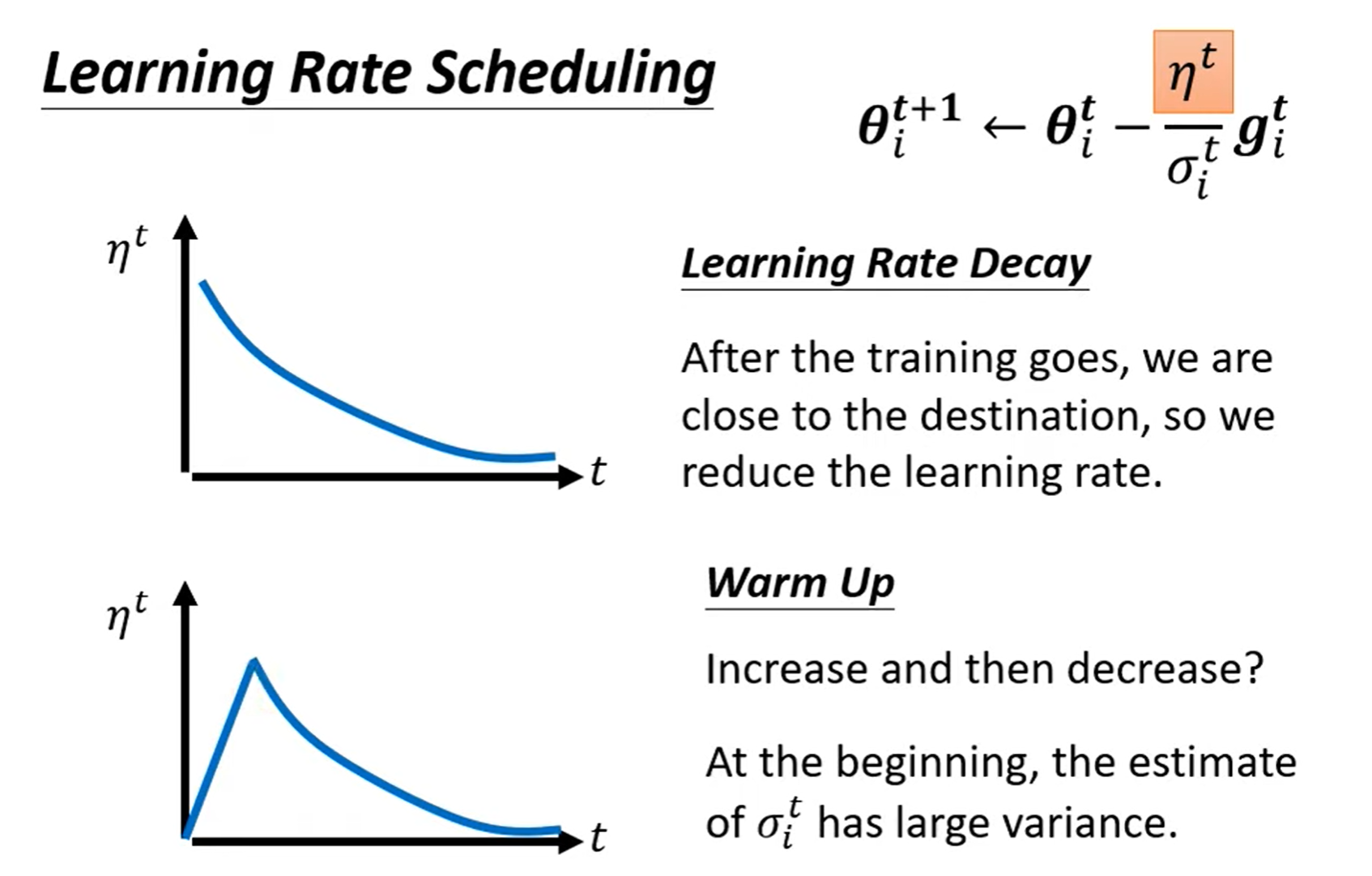
Larning Rate Decay
As the trainging goes, we are closer to the destination, so we reduce the learning rate.
Warm Up
地球大爆炸?
Increase and then decrease.
黑科技QAQ,会有比较好的结果。
Transformer 中也有用到。
Summary of Optimization¶

\(\sigma\) 对参数进行特制化,主要考虑大小
Momentum 不只看当前梯度,还考虑上一步的 movement。
还能让 \(\eta\) 随时间变化
Classification¶
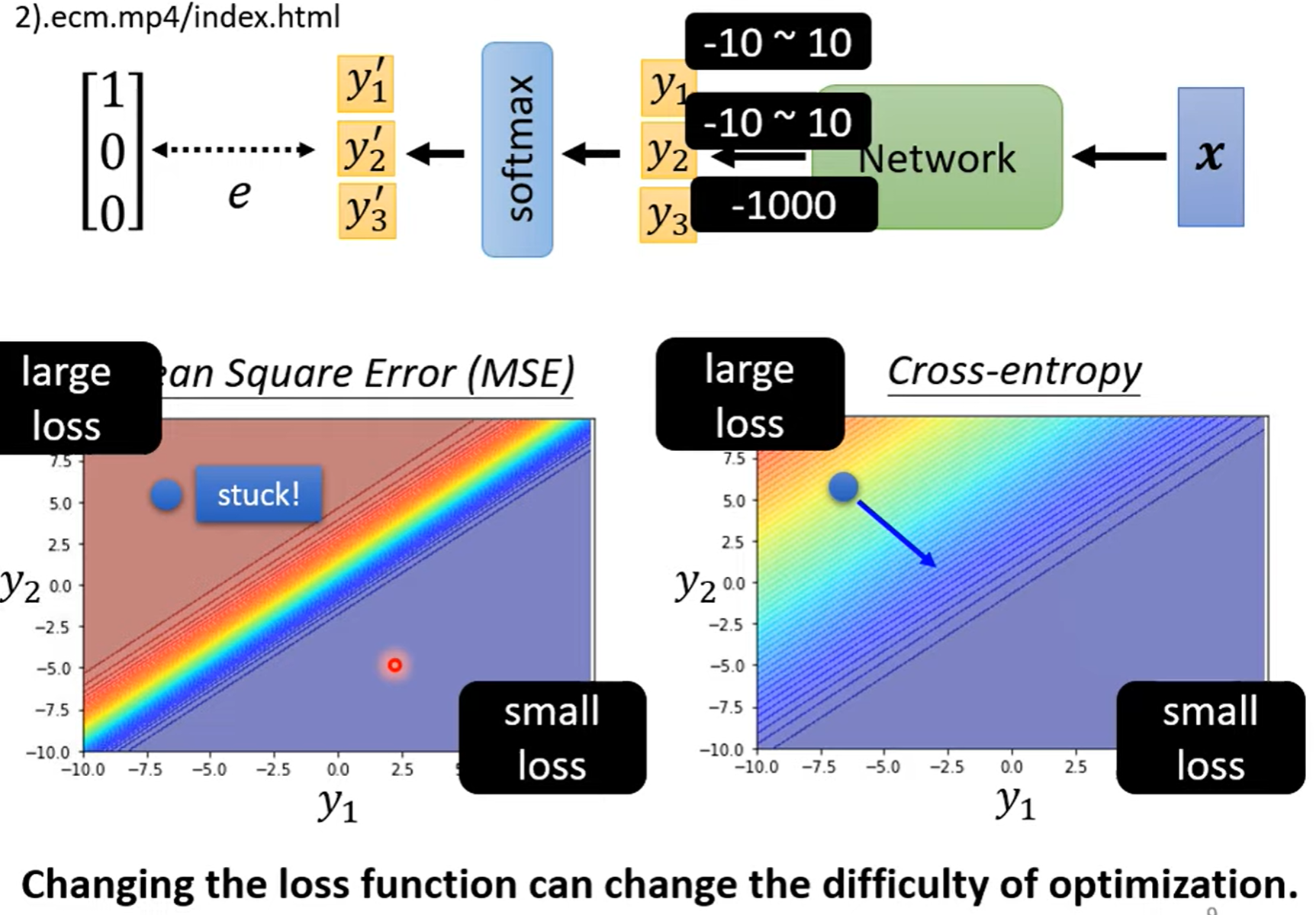
Class as one-hot vector
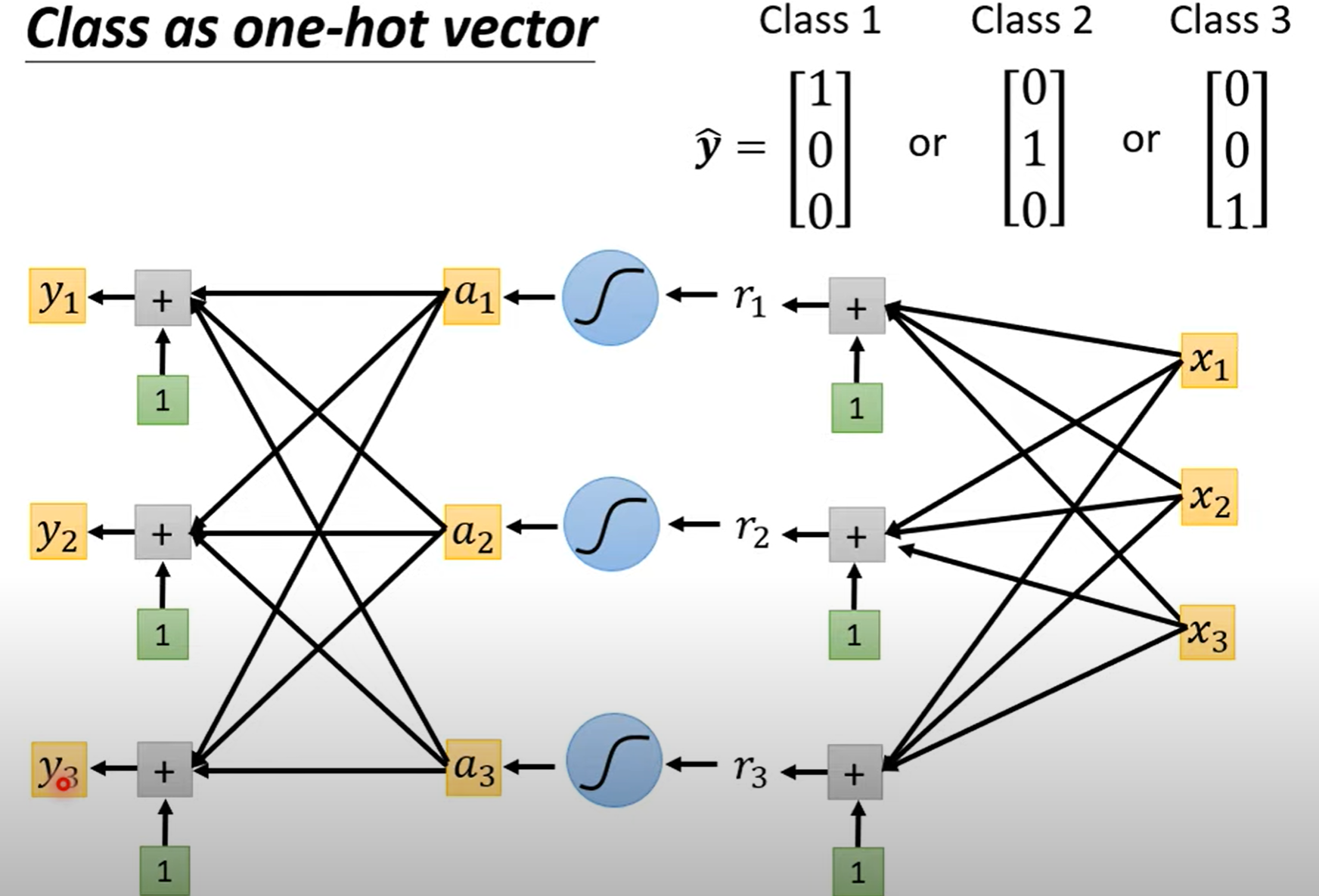
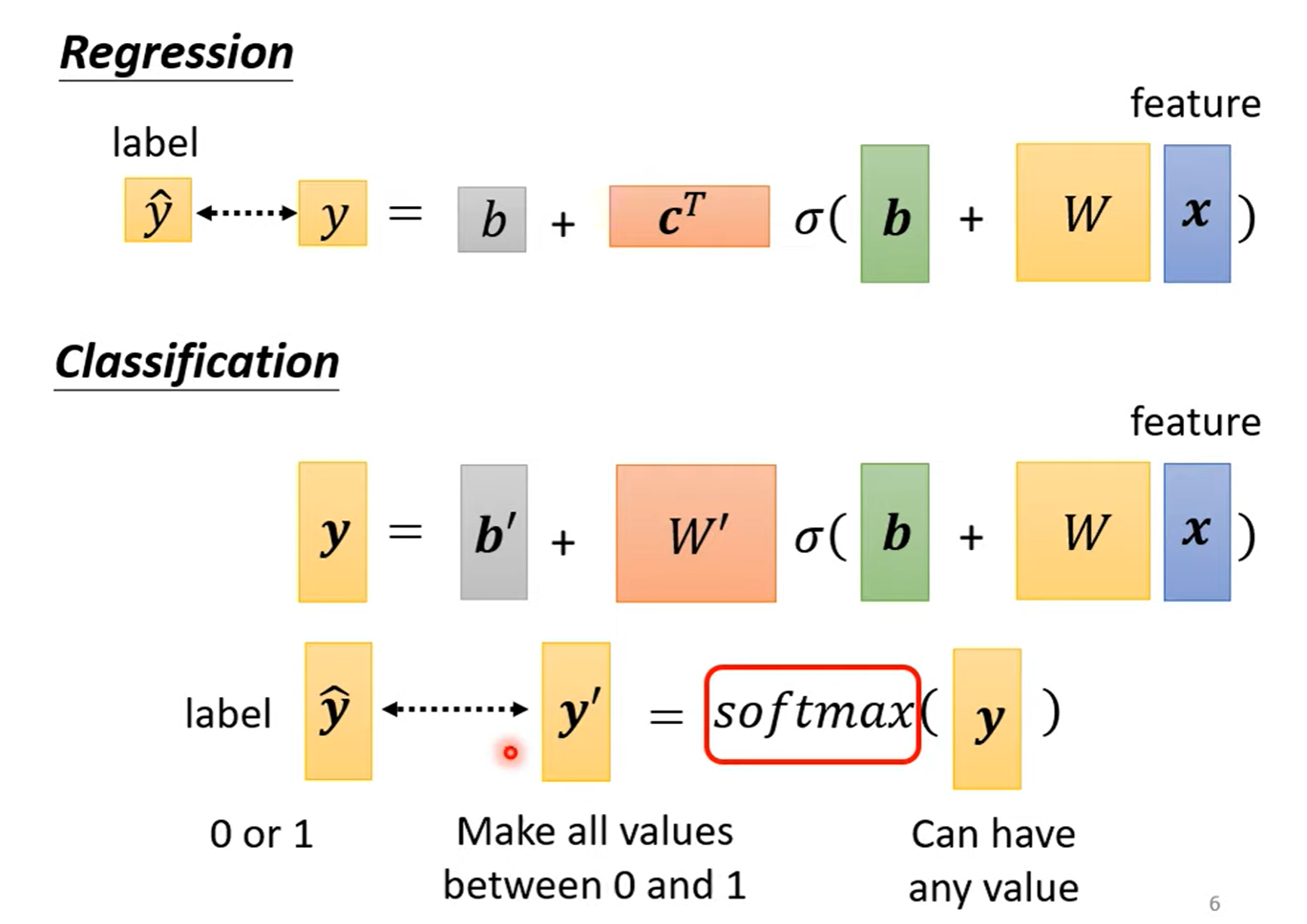
在regression中,直接拿输出数值 y和真实数值计算接近度;而在 classification中,是将多个输出数值组成一个向量,向量经过 softmax 后形成新的向量,再拿新的向量去和不同类别计算接近度。softmax的含义可以简单理解成将含有各种各样数值的向量 \(y\) 转变成只含有 \(0\) 和 \(1\) 的向量 \(y'\)
Loss of Classification¶
Minimizing cross-entropy(交叉熵) is equivalent to maximizing likelihood(最大似然).
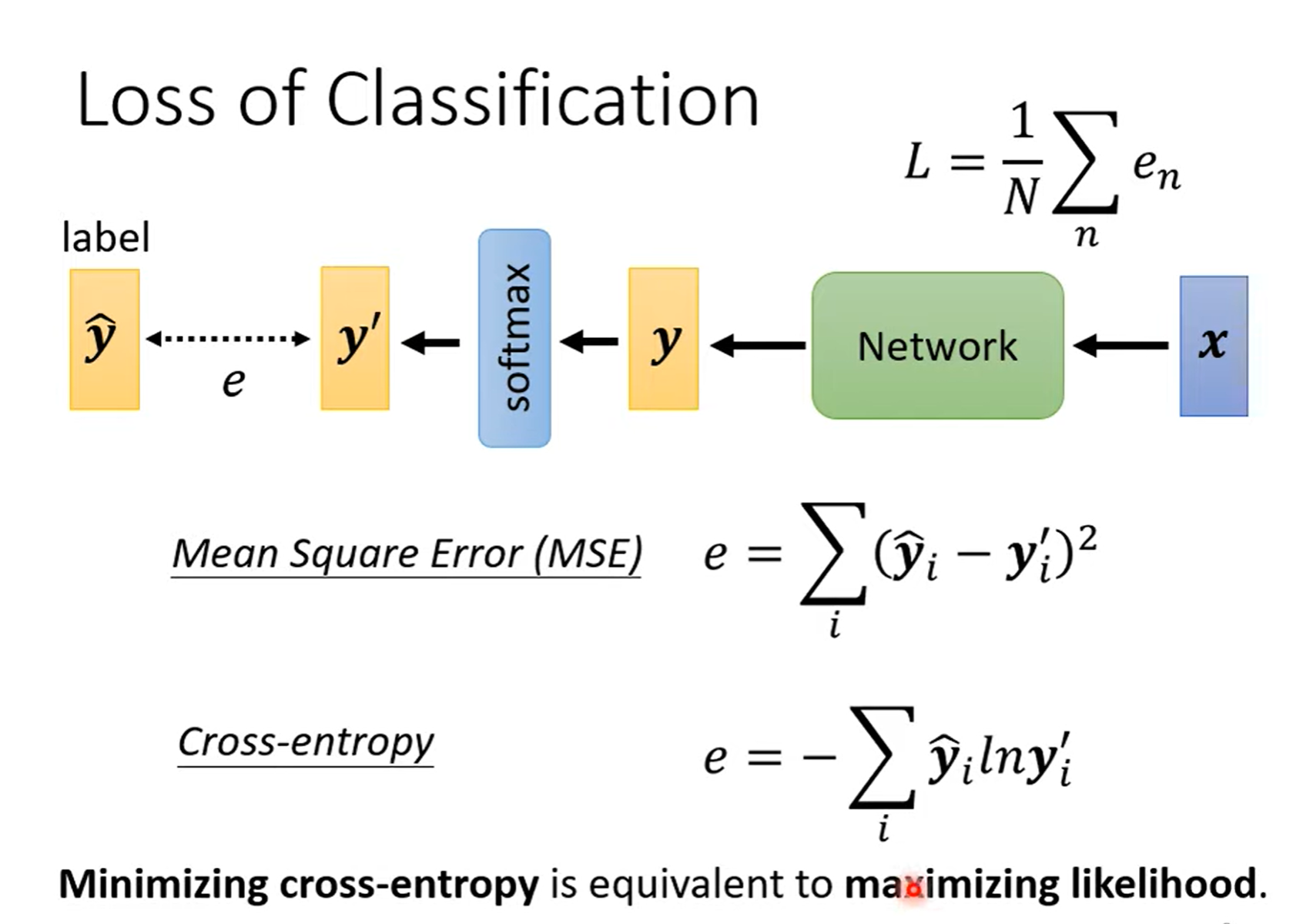
常用 cross-entropy + softmax 组合使用。
采用交叉熵改变了 loss 函数,也就改变了 error surface,使得在大loss 的地方也会有大的 gradient,而不像
MSE 在大 loss 处的 gradient很小,不易梯度下降。所以交叉熵计算出来的 loss 函数更容易做梯度下降,不容易卡住!
Created: January 3, 2024