Raft¶
约 1700 个字 54 行代码 预计阅读时间 6 分钟
Heartbeat RPCs:a leader occasionally (at least once per heartbeat interval) send out an AppendEntries RPC to all peers to prevent them from starting a new election.
Lab 2A¶
// create a new Raft server instance:
rf := Make(peers, me, persister, applyCh)
// start agreement on a new log entry:
rf.Start(command interface{}) (index, term, isleader)
// ask a Raft for its current term, and whether it thinks it is leader
rf.GetState() (term, isLeader)
// each time a new entry is committed to the log, each Raft peer
// should send an ApplyMsg to the service (or tester).
type ApplyMsg
Make(peers, me, persister, applyCh)
- peers:包含所有 Raft peers 的网络标识符的数组,用于进行 RPC 通信
- me:该 raft peer 在 peers 数组中的 index
Start(command)
- 将命令 append 到 replicated log 中,无需等待 append 完成,立即返回(给日志追加开一个单独的线程)
ApplyMsg
- 每次提交新的 log entry 到 log 时,raft peer 都要发送 ApplyMsg 给
applyCh通道中(Make 创建的)
使用 src/labrpc 中的 RPC 进行通信。
Task¶
Implement Raft leader election and heartbeats (AppendEntries RPCs with no log entries). The goal for Part 2A is for a single leader to be elected, for the leader to remain the leader if there are no failures, and for a new leader to take over if the old leader fails or if packets to/from the old leader are lost. Run go test -run 2Ato test your 2A code.
实现领导选举和心跳检测。
You can't easily run your Raft implementation directly; instead you should run it by way of the tester, i.e. go test -run 2A.
Follow the paper's Figure 2. At this point you care about sending and receiving RequestVote RPCs, the Rules for Servers that relate to elections, and the State related to leader election,
Add the Figure 2 state for leader election to the Raft struct in raft.go. You'll also need to define a struct to hold information about each log entry.
完善 Raft 和 log entry 的 Struct
Role Transition
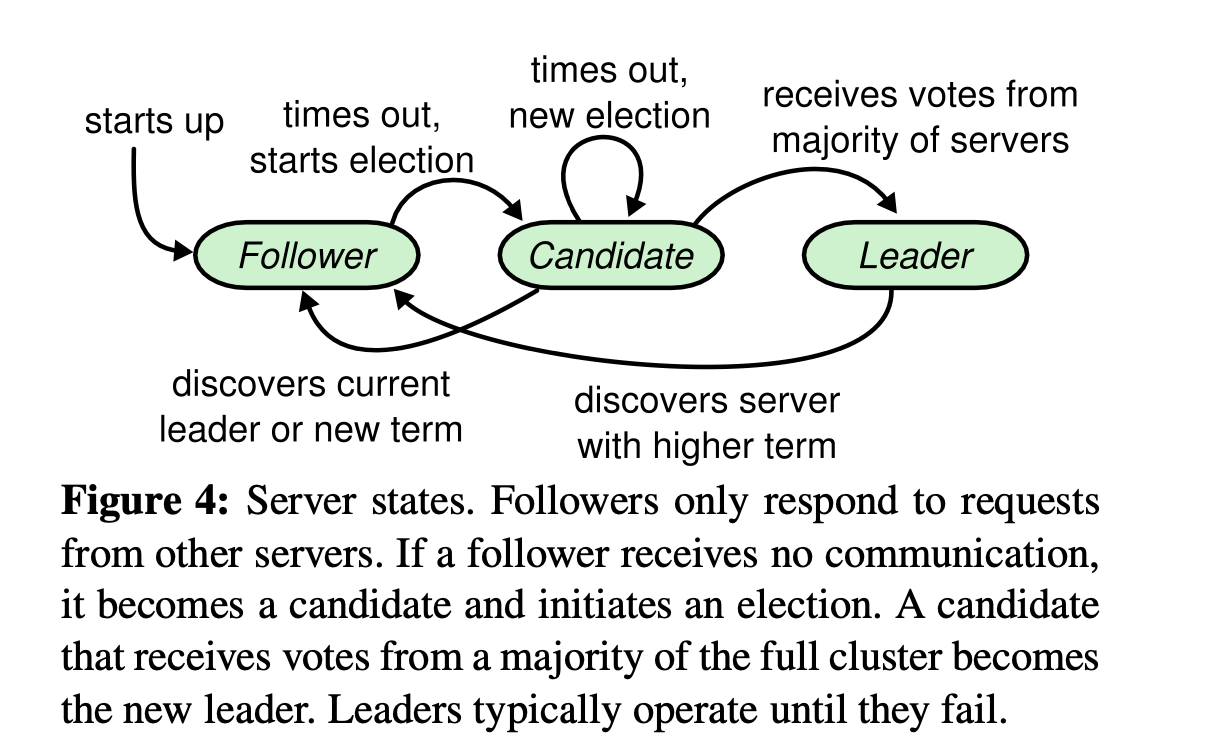
- Follower 只想相应来自其他节点的请求。
- 如果 Follower 没有进行通信的话,就变成 Candidate 并且初始化一轮 election。
- Candidate 收到大多数选票就会成为新的 Leader,直到 fail。
Log Entry
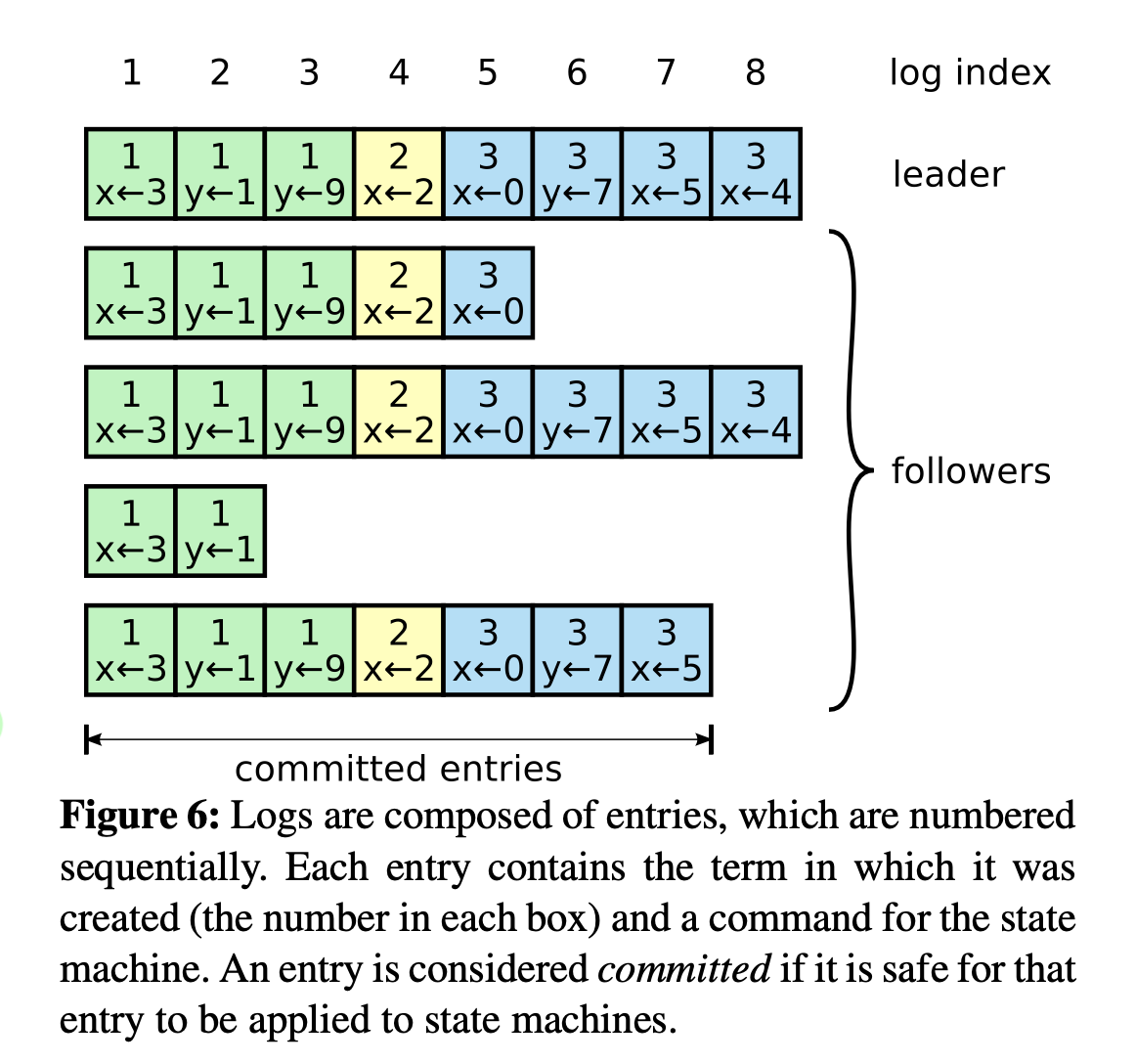
-
command
-
term number received by Leader: be used to detect inconsistencies
-
Each log entry also has an integer index identifying its position in the log. (在 raft 节点的 logs 中)
-
committed 状态:表征是否被复制状态机接收到。
-
go type LogEntry struct { term int // term number received by Leader command interface{} // command for state machine committed bool // true if it is safe for that entry to be applied to state machines. }
Fill in the RequestVoteArgs and RequestVoteReply structs. Modify Make() to create a background goroutine that will kick off leader election periodically by sending out RequestVote RPCs when it hasn't heard from another peer for a while. This way a peer will learn who is the leader, if there is already a leader, or become the leader itself. Implement the RequestVote() RPC handler so that servers will vote for one another.
补充 RPC 的结构体信息
RequestVoteArgs
go type RequestVoteArgs struct { Term int // candidate's term CandidateId int // candidate requesting vote LastLogIndex int // index of candidate's last log entry LastLogTerm int // term of candidate's last log entry }RequestVoteReply
go type RequestVoteArgs struct { Term int // candidate's term CandidateId int // candidate requesting vote LastLogIndex int // index of candidate's last log entry LastLogTerm int // term of candidate's last log entry }修改 Make() 函数,创建一个周期函数,当节点在一定时间没有收到通信,会启动一次选举,并发送 RequestVote 的 PRC 请求。这样做的目的是,该节点会知道谁是 Leader:
- 原本存在 Leader
- 自己成为 Leader
实现 RequestVote 的RPC:节点可以给其他节点投票。
初始化状态:
// When servers start up, they begin as followers.
rf.role = Follower
rf.currentTerm = 0
rf.votedFor = -1
周期函数:如果该节点一段时间没收到心跳检测,则启动一次选举
func (rf *Raft) ElectionTicker() {
for rf.killed() == false {
// Your code here to check if a leader election should
// be started and to
rf.mu.Lock()
if rf.role != Leader && rf.isElectionTimeout() {
rf.becomeCandidate()
// start a new election
go rf.startElection(rf.currentTerm)
}
rf.mu.Unlock()
// randomize sleeping time using time.Sleep().
ms := 50 + (rand.Int63() % 300)
time.Sleep(time.Duration(ms) * time.Millisecond)
}
}
要票的逻辑和结构体参数要求都在论文中写的很清楚了。

- 当前候选者碰到了更高任期的 peer,则降级为 Follower ,同时更新他的 term,保持节点跟上最新节点的状态。
To implement heartbeats, define an AppendEntries RPC struct (though you may not need all the arguments yet), and have the leader send them out periodically. Write an AppendEntries RPC handler method that resets the election timeout so that other servers don't step forward as leaders when one has already been elected.

根据论文完善 AppendEntries 进行 RPC 需要的 args 和 reply
-
在进行心跳检测的时候,如果发现有更高任期的 peer,会停止当前的 AppendEntries。(这时候当前的 term 已经过期了,有了新的 Leader),只有 Leader 才可以进行 AppendEntries。
-
go func (rf *Raft) isContextLost(role Role, term int) bool { return rf.role != role || rf.currentTerm != term } -
定义上面的函数,用来判断是否过期,是否不是 Leader 了。
完善 AppendEntries 函数:实现 reset the election timeout.
- 重置 开始时间和 持续时间
Make sure the election timeouts in different peers don't always fire at the same time, or else all peers will vote only for themselves and no one will become the leader.
- election timeout 在一定范围内随机
The tester requires that the leader send heartbeat RPCs no more than ten times per second.
The tester requires your Raft to elect a new leader within five seconds of the failure of the old leader (if a majority of peers can still communicate). Remember, however, that leader election may require multiple rounds in case of a split vote (which can happen if packets are lost or if candidates unluckily choose the same random backoff times). You must pick election timeouts (and thus heartbeat intervals) that are short enough that it's very likely that an election will complete in less than five seconds even if it requires multiple rounds.
- election timeout 和 heartbeat intervals 的时间要合理,使得在
旧Leader出现故障后的 5 秒 内选出新的 Leader。
Don't forget to implement GetState().
- return currentTerm and isLeader
- 让 tester 知道选出了 Leader
Lab 2B¶
论文¶
Once a leader has been elected, it begins servicing client requests.
一旦 Leader 当选,开始处理 client 的请求。
-
每个客户端的请求包含 command
-
Leader appends the command to its log as a new entry, then issues AppendEntries RPCs in parallel to each of the other servers to replicate the entry.

Leader 把 command 封装到 LogEntry 中,然后通过 RPC 并行的发送给其他节点。
-
When the entry has been safely repl;icated,the leader applies the entry to its state machine and returns the result of that execution to the client.
当 client 成功收到该 Entry (即 safely replicated)后,Leader 修改他自己的状态机(Logs),并将执行结果返回给 client,follower 收到之后就到自己的状态机
safely replicated:
- 当该 Entry 被大多数节点 replicated 之后,即可认为是该 Entry 是 committed 的,也就是 safely replicated。
-
如果 client 因为 crash/timeout 的原因没有接受到,Leader 会重发,直到所有的 follower 都收到。

Raft 机制使得多个节点上保持高度一致性。
-
If two entries in different logs have the same index and term, then they store the same command.
log entries never change their position in the log.
-
If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.
If the follower does not find an entry in its log with the same index and term, then it refuses the new entries.
当 Leader 发送 AppendEntries 请求给 Follower 时,会附带一个一致性检查信息:即包含前一个日志条目的索引(LogIndex)和任期号(prevLogTerm)。这就使得 Follower 能够判断自己的日志是否与 Leader 一致。
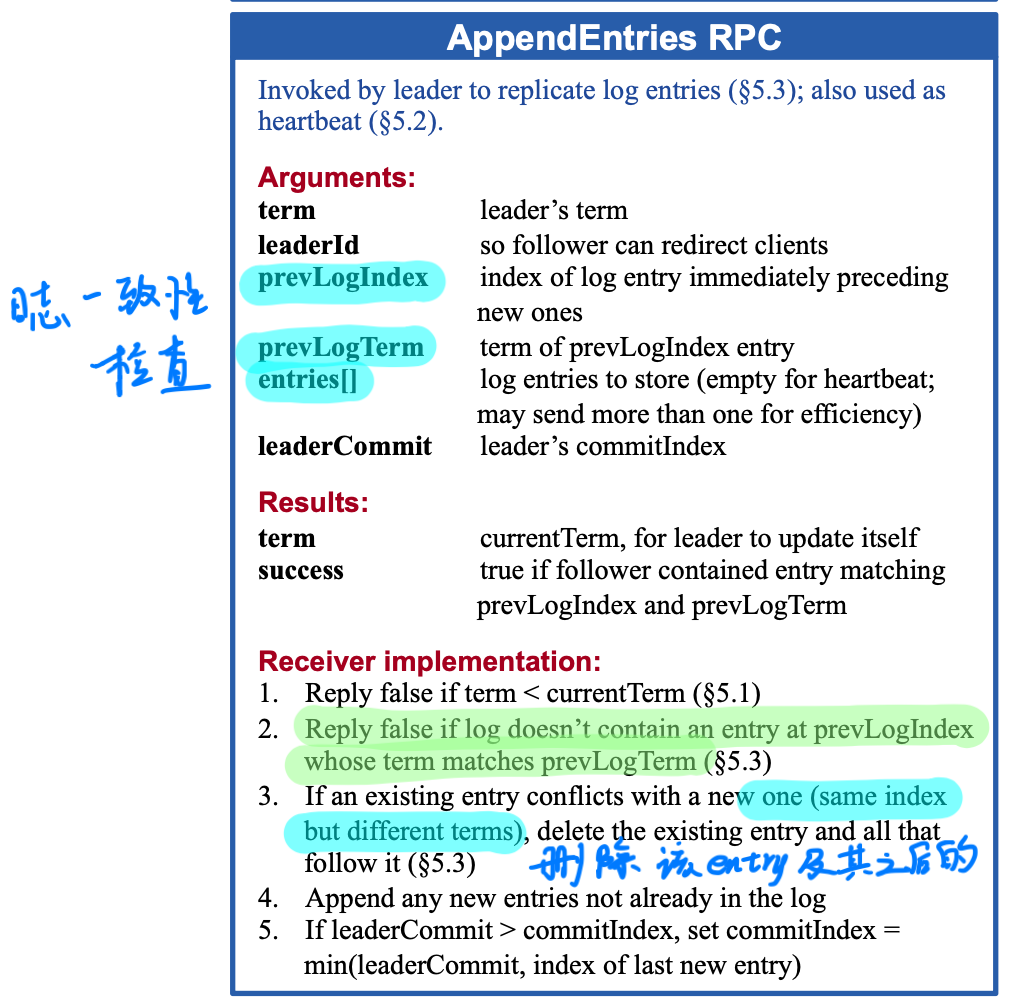
The leader maintains a nextIndex for each follower, which is the index of the next log entry the leader will send to that follower.

- When a leader first comes to power, it initializes all nextIndex values to the index just after the last one in its log
- If a follower’s log is inconsistent with the leader’s, the AppendEntries consis- tency check will fail in the next AppendEntries RPC. Af- ter a rejection, the leader decrements nextIndex and retries the AppendEntries RPC.
With this mechanism, a leader does not need to take any special actions to restore log consistency when it comes to power.
-
A leader never overwrites or deletes entries in its own log
-
It just begins normal operation, and the logs auto- matically converge in response to failures of the Append- Entries consistency check。
follower 会主动跟随 Leader 的 log,并保持一致。
Leader 只需要考虑能不能当选就好啦
Task¶
Your first goal should be to pass TestBasicAgree2B(). Start by implementing Start(), then write the code to send and receive new log entries via AppendEntries RPCs, following Figure 2. Send each newly committed entry on applyCh on each peer.
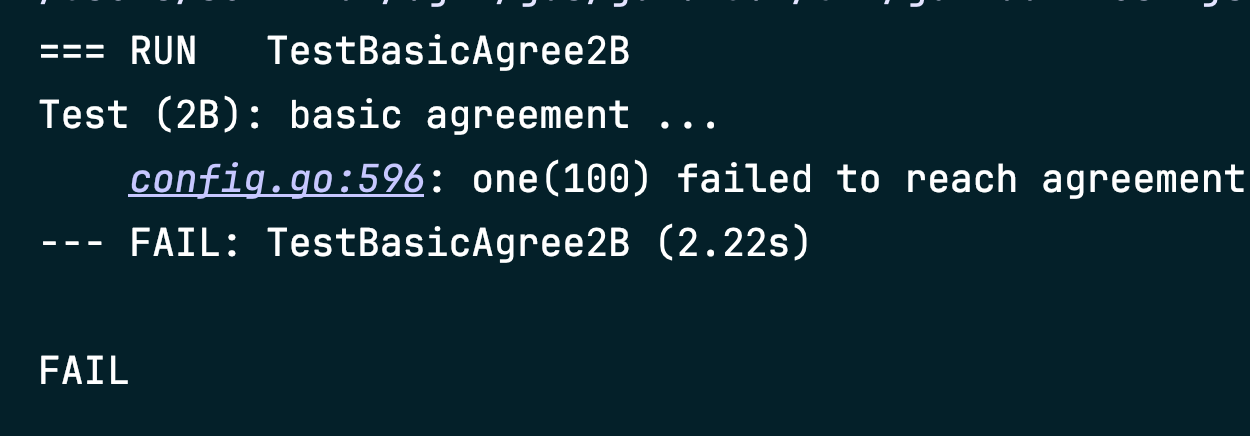
One way to fail to reach agreement in the early Lab 2B tests is to hold repeated elections even though the leader is alive. Look for bugs in election timer management, or not sending out heartbeats immediately after winning an election.
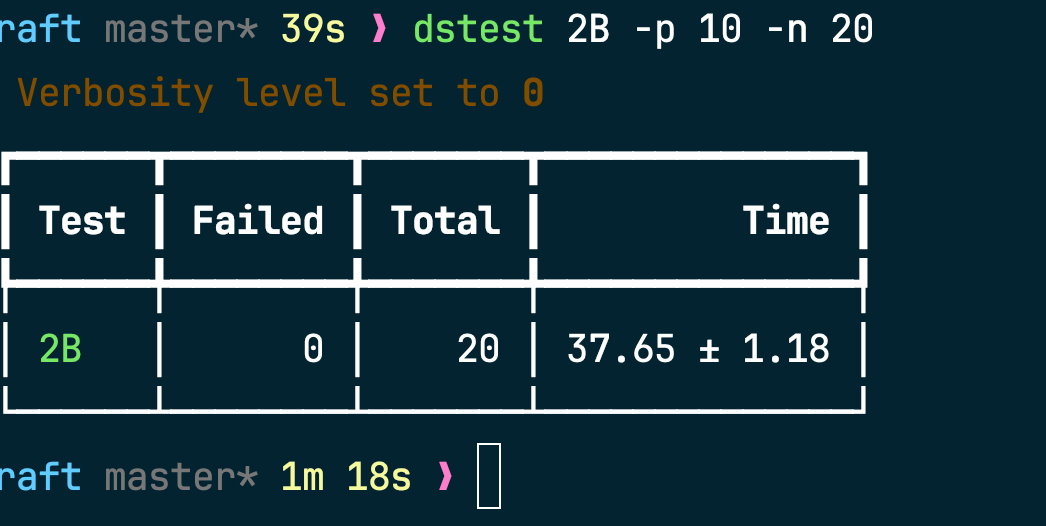
成为领导者后心跳检测:
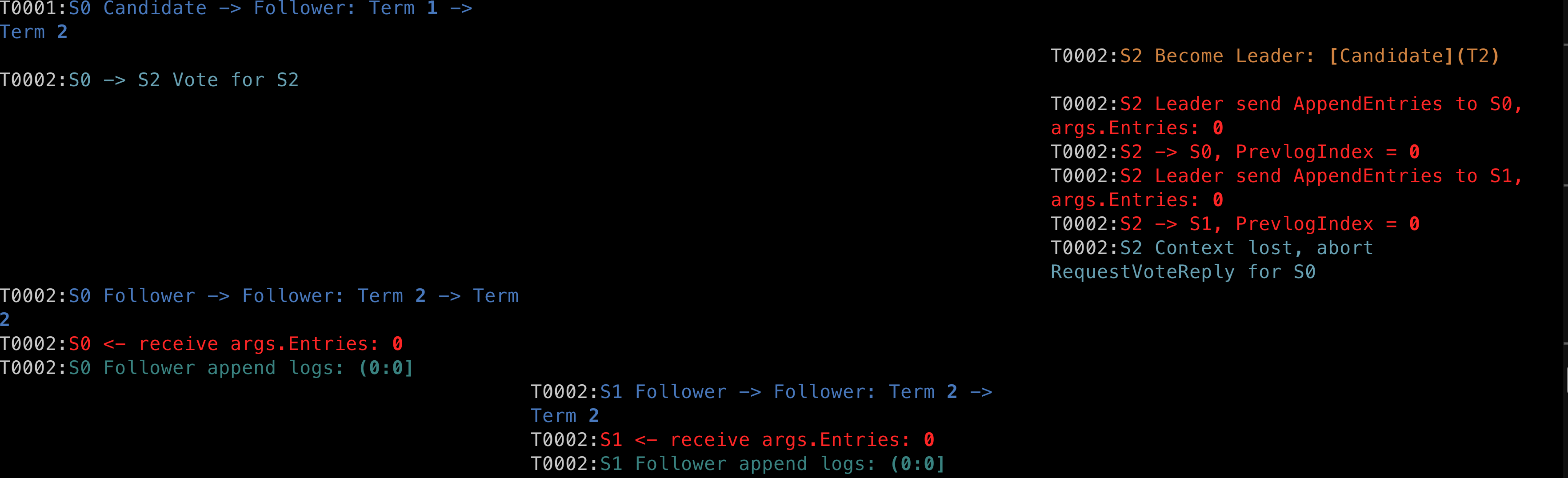
这里的 PrevLogIndex 有点问题

下图第二张的 PrevLogIndex 应该是零的。
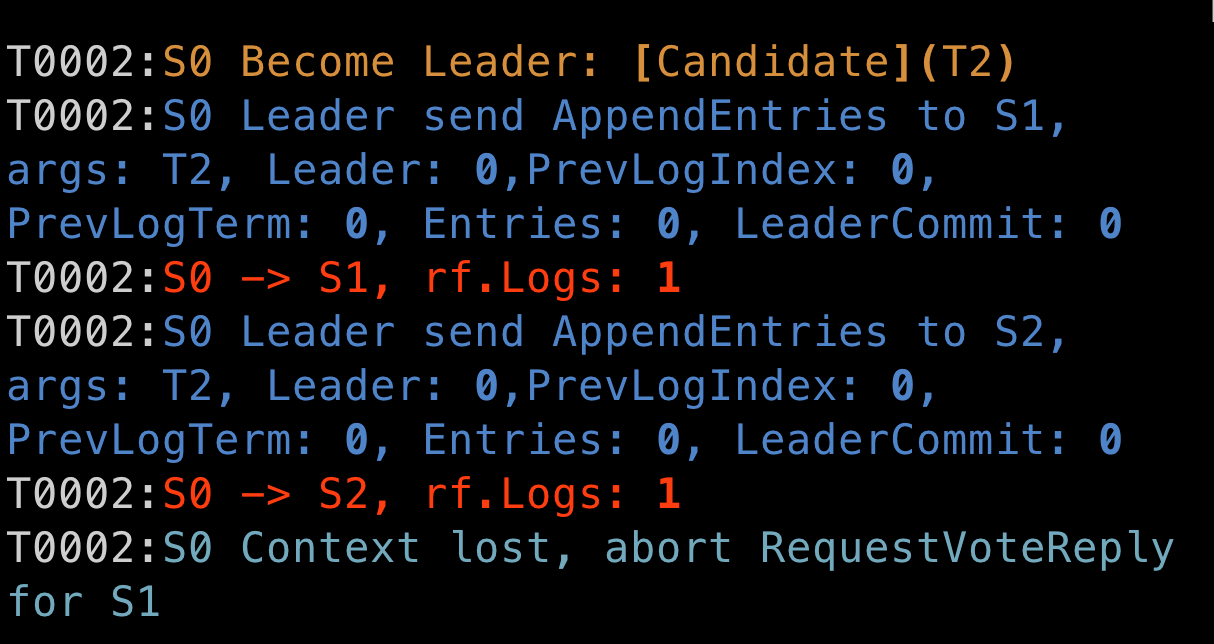
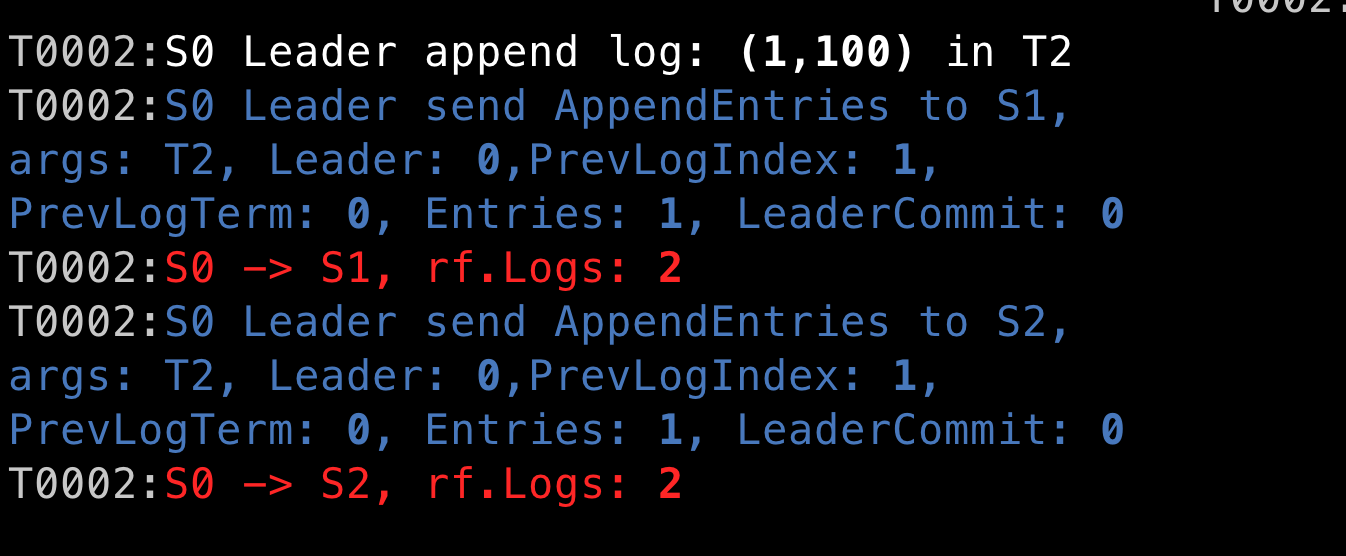
原因是 log application 还没做qwq
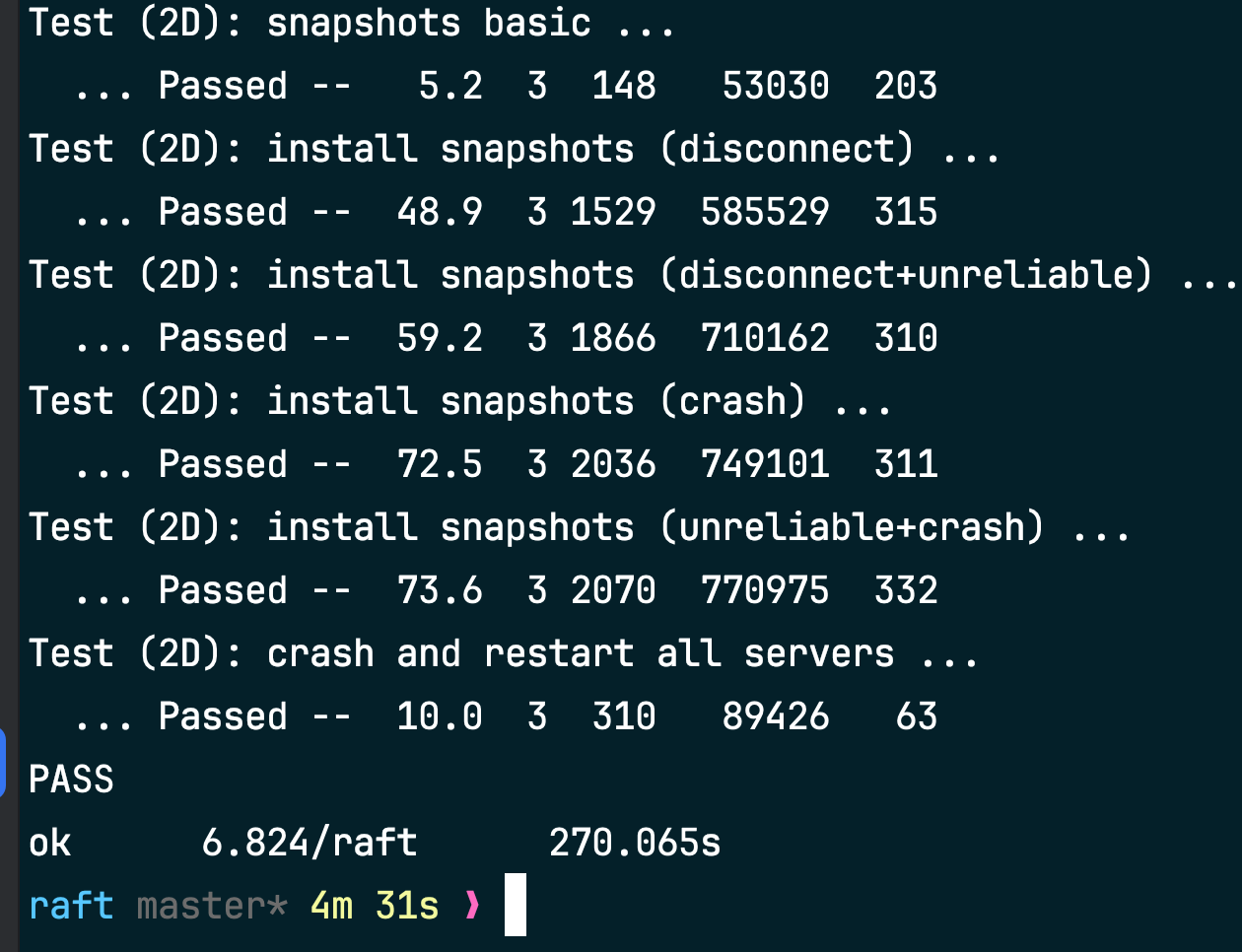
Lab 2D¶
Last update: June 27, 2025
Discussion