鱼书¶
约 449 个字 26 行代码 预计阅读时间 2 分钟
Reference¶
oreilly-japan/deep-learning-from-scratch
Activate function¶
激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。
下面是激活函数存在的几个关键原因:
-
增加模型的表达能力:通过使用 非线性激活函数,神经网络可以学习并模拟任何复杂度的函数,理论上能够近似任何类型的连续函数。这种性质被称为神经网络的 通用逼近定理。
-
帮助决策:在分类问题中,非线性激活函数如 Sigmoid或Softmax可以将网络的输出转换为概率分布,这有助于决策过程。例如,Sigmoid可以将任意值压缩到0和1之间,便于执行二分类。
-
控制信息的流动:某些非线性激活函数(如ReLU及其变种)可以帮助控制信息在网络中的流动,通过 在某些情况下“关闭”神经元的输出,这有助于减少过拟合和计算复杂性。
softmax 函数的输出是 0.0 到 1.0 之间的实数。并且,softmax 函数的输出值的总和是 1 ,可以把 softmax 函数的输出解释为 “概率”。
def step_function(x):
return np.array(x > 0, dtype=np.int)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_grad(x):
return (1.0 - sigmoid(x)) * sigmoid(x)
def relu(x):
return np.maximum(0, x)
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 防止溢出
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
Learn from Data¶
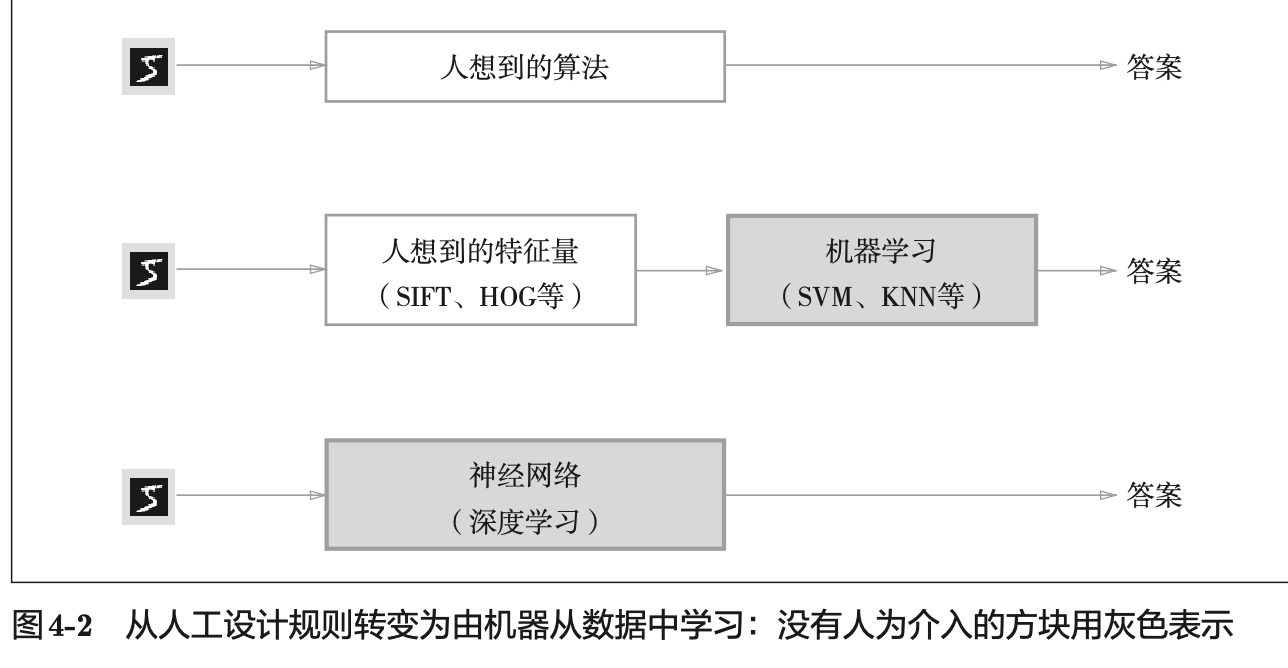
Loss Function¶
均方误差(mean squared error)
$$
E = \frac{1}{2} \sum_{k}(y_k - t_k)^2 \
$$
这里,\(y_k\) 是表示神经网络的输出,\(t_k\) 表示监督数据,\(k\) 表示数据的维数。
交叉墒误差(cross entropy error)
$$
E = - \sum{t_k \log y_k}
$$
若采用 one-hot 标签,实际上只计算对应正确解标签的输出的自然对数。
Gradient descent¶
学习率(lr,learning rate):学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。
def gradient_descent(f,init_x,lr = 0.01,step_num):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f,x)
x -= lr * grad
return x
Created:
April 5, 2024
Last update: April 24, 2026
Last update: April 24, 2026
Discussion