第三章 SQL¶
约 1530 个字 126 行代码 预计阅读时间 7 分钟
特点:综合统一,高度非过程化,面向集合的操作方式,语言简洁、易学易用。
SQL 的基本概念¶
三级模式结构:
- 外模式:视图
- 模式:基本表
- 内模式:存储文件
基本表
- 本身独立存在的表。
- 一个关系对应一个基本表。
- 一个(或多个)基本表对应一个存储文件。
视图
- 视图是一个虚表。
- 从基本表/视图导出的表。
- 数据库中只存在视图的定义而不存放对应的数据。
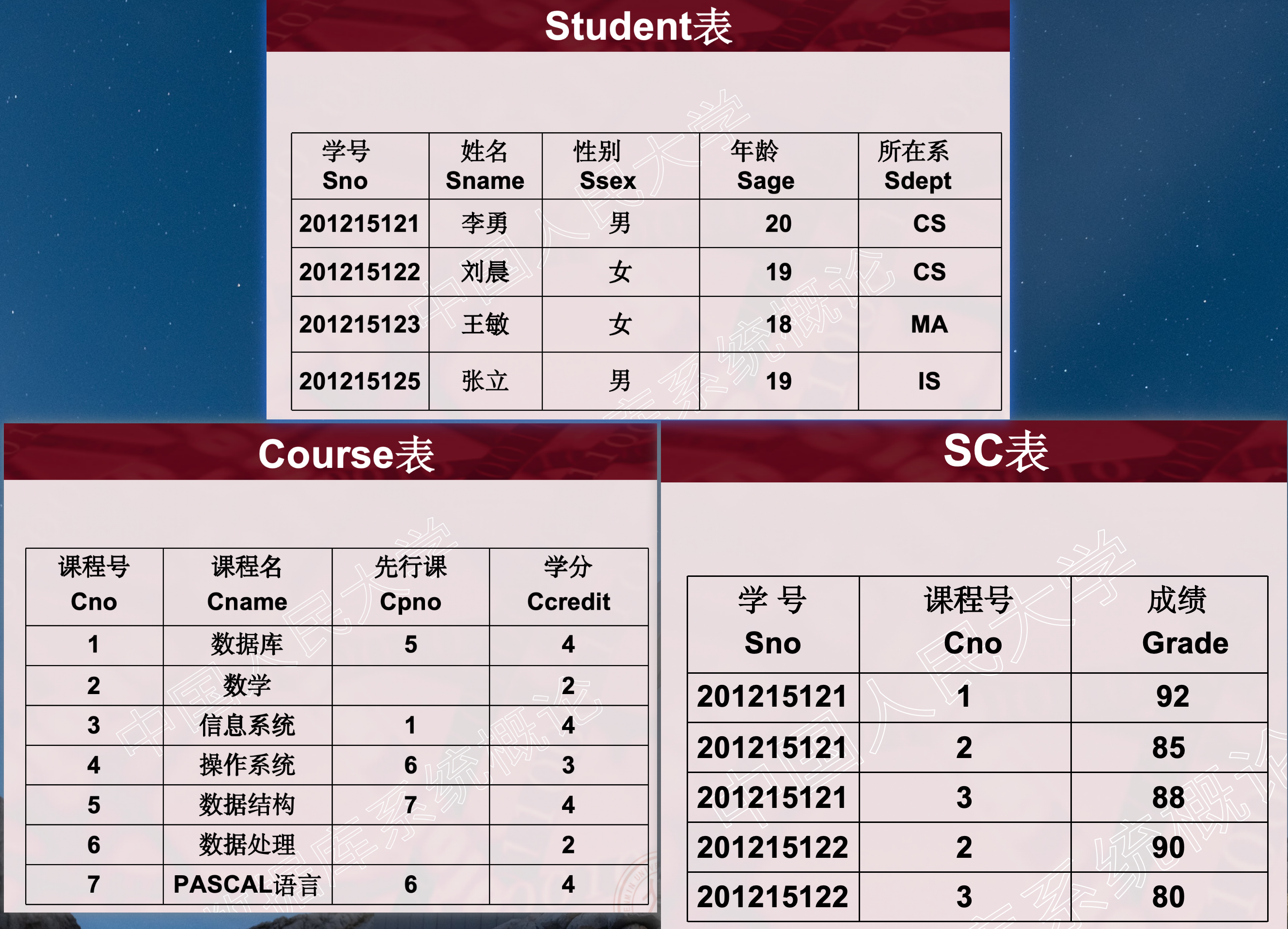
Student-Course-SC 表¶
数据定义¶
| 操作对象 | 创建 | 删除 | 修改 |
|---|---|---|---|
| 模式 | CREATE SCHEMA | DROP SCHEMA | |
| 表 | CREATE TABLE | DROP TABLE | ALTER TABLE |
| 视图 | CREATE VIEW | DROP VIEW | |
| 索引 | CREATE INDEX | DROP INDEX | ALTER INDEX |
模式¶
创建模式:create schema <模式名> authorization <用户名>
删除模式:drop schema <模式名> <cascade | restrict>
- Cascade : 级联,连同该模式中所有的数据全部删除
- Restrict :限制,只有模式为空时(不含表,视图等),才能删。
基本表¶
创建
create table <表名>
(
<列名> <数据类型> [<列级完整性约束条件>],
<列名> <数据类型> [<列级完整性约束条件>],
<表级完整性约束条件>
)
create table Cource
(
Cno Char(4) primary key,
Cname Char(40) unique,
Cpno Char(4),
/* 先修课 Cpno 是外码, 参考 Cno */
foreign key (Cpno) references Course(Cno),
)
如果有主码有多个属性构成,必须作为表级完整性进行定义 primary key (Sno,Cno)
删除
基本表被删除,表上的数据,视图,触发器都被删除。
修改
alter table <表名>
[add [column] <新列名> <数据类型> <完整性约束>]
[add <表级完整性约束条件>]
[drop [column] <列名> <cascade | restrict>]
[drop constraint <完整性约束名> <cascade | restrict>]
[alter column <列名> <属性名>]
索引¶
数据库会在 primary key 和 unqiue 上自动建立索引。
索引是关系数据库内部实现技术,属于内模式的范畴。
建立索引
聚簇索引: 索引顺序与表中记录的物理顺序一致
- 一个表上最多一个聚簇索引
- 逻辑顺序和物理顺序一致
- 查询效率高
删除索引
数据查询¶
where子句¶

字符匹配就是 模糊查询,其中 % 是任意长度通配符,_ 表示一个字符。
- 如果查询字符中有
_,则加转义字符,例:select * from Course where Cname like 'DB\_Design' escape '\'。escape '\'表示\是转义字符。
逻辑运算: AND 的优先级高于 OR
例句
查询全体学生的姓名,出生年份,要求用小些字母表示所有系名
- select Sname,2014 - Sage, lower(Sdept) from Stduent;
字符要加单引号 查询计算机科学系全体学生的名字 - select Sname from Student where Sdept='CS';
模糊查询 查询所有性刘学生的姓名、学号和性别 - select Sname,Sno,Ssex from student where Sname like '刘%'
逻辑运算 查询计算机系年龄在20岁以下的学生姓名 - select Sname from Student where Sdept='CS' and Sage<20;
order by子句¶
升序:ASC,降序:DESC,缺省值为升序。
例句
查询全体学生情况,查询结果按所在系的系号升序,统一系中的学生按年龄降序排列。
- select * from Student order by Sdept ASC,Sage DESC;
聚集函数¶
聚集函数只能用于 select 子句和 group by 的 having 子句,不能用于where子句的条件表达式
-
统计元组个数 :
COUNT(*) -
统计一列中值的个数:
COUNT([DISTINCT|ALL] <列名>) -
计算一列值的总和(此列必须为数值型):
SUM([DISTINCT|ALL] <列名>) -
计算一列值的平均值(此列必须为数值型):
AVG([DISTINCT|ALL] <列名>) -
求一列中的最大值:
MAX([DISTINCT|ALL] <列名>)
group by子句¶
对查询结果分组后,聚合函数 将分别作用于每个组
例题
求各个课程号及相应的选课人数
- select Cno,count(Sno) from SC group by Cno;
Select 后面只能跟 聚合函数和分组的依据(Cno)
查询选修了3门以上课程的学生学号
- select Sno from SC group by Sno having count(*) > 3;
连接查询¶
自身连接
一个表与其自己进行连接
- 需要给表起别名以示区别
查询每门课程的先修课。
select FIRST.SNO , SECOND.Cpno
from Course FIRST, COURSE SECOND
where FIRST.Cpno = SECOND.Cno
外连接
左外连接:列出左边关系中所有的元组。left out join <表名> on
右外连接:列出右边关系中所有的元组。right out join <表名> on
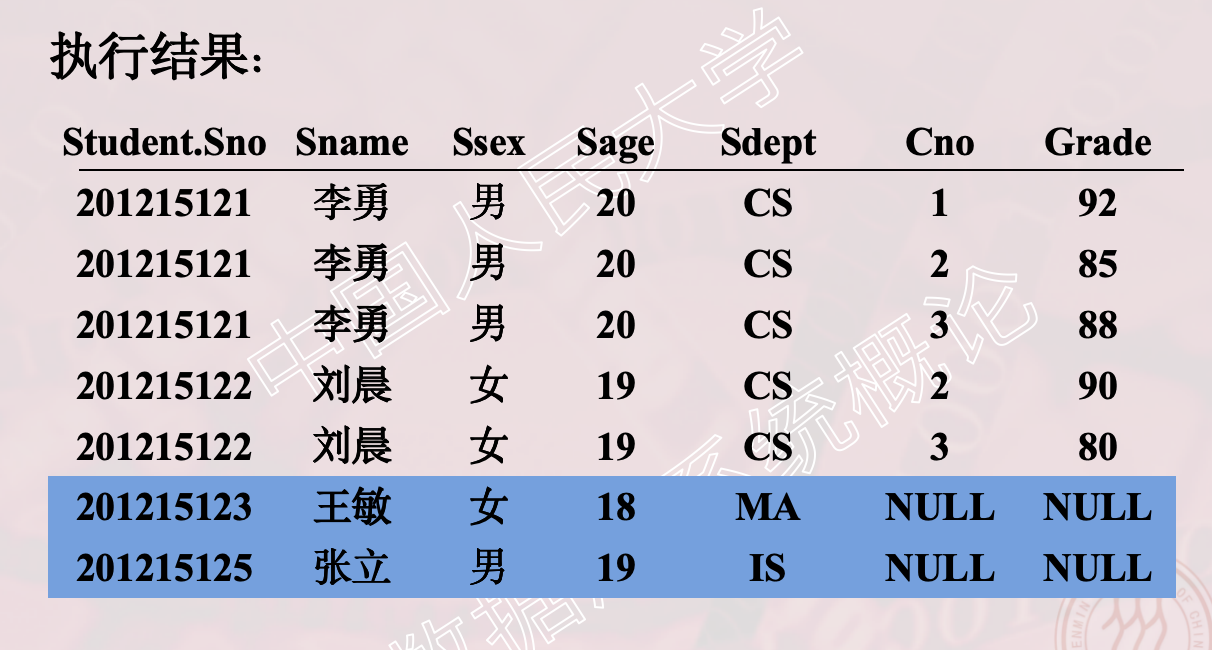
查询每个学生及其选修课程的情况
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student LEFT OUT JOIN SC
ON (Student.Sno=SC.Sno);
嵌套查询¶
将一个查询块嵌套在另一个查询块的 where 子句和 having 子句短语的条件中的查询
- 外层查询(父查询),内层查询(子查询)
- 子查询中不能使用
order by子句
子查询的结果往往是个集合,用 in 谓词作连接
- 不相关子查询
- 相关子查询:子查询的查询条件依赖于父查询
找出每个学生超过他选修课程平均成绩的课程号
# 相关子查询,子查询中 x.Sno 需要父查询提供
select Sno,Cno
from SC x
where Grade >=
(
select AVG(Grade)
from SC y
where x.Sno = y.Sno
);
ANY,ALL 谓词
ANY :任意一个值
ALL : 所有值
查询非计算机科学系中比计算机科学 任意 一个学生年龄小的学生的 姓名和年龄
# 任意用 ANY 谓词,所有用 ALL 谓词
select Sname, Sage
from Student
where Sage < ANY
(select Sage from Student where Sdept='CS')
and Sdept != 'CS'
EXISTS 谓词
EXISTS 谓词返回 true 或 false,以此来作为选不选的依据。
- 由
EXISTS引出的子查询列表都用*,给出列名无实际意义。
查询没有选修1号课程的学生姓名。
select Sname
from Student
where not exists
(
select * from SC
where Sno = Student.Sno and Cno = '1'
);
全称量词
双重否定表示肯定,下面的例子:一个学生每门课选了,中间加两个 not exists。
$$
(\forall x)P \equiv \lnot \,(\,\exists \,x (\,\lnot P \,)\,)
$$
查询选修了全部课程的学生姓名。
等价于:没有一门课程是他不选的
select Sname from Student
where not exists
(
select * from Course
where not exists
(
select * from SC
where Sno = Student.Sno and Cno = Course.Cno
)
);
至少
过程如下所示
- 遍历 SCX 的每门课程所选的 学号 x ,找出不符合的情况
- 学生 201215122 选了,并且 学号 x 没选
查询至少选修了学生 201215122 选修的全部课程的学生学号
等价于:不存在这样的课程 y,学生 201215122 选了,而学生 x 没有选
select distinct Sno from SC SCX
where not exists
(
select * from SC SCY
where SCY.Sno = '201215122'
and not exists
(
select * from SC SCZ
where SCZ.Sno = SCX.Sno
and SCX.Cno = SCY.Cno
)
)
集合查询¶
集合操作的种类:并操作 union,交操作 intersect,差操作 expect
union,自动去掉重复元组,union all保留全部元组- 并操作和
or差不多,交操作和and差不多 - 参加集合操作的列数和列的数据类型必须相同
数据更新¶
插入数据¶
insert into <表名> [属性列] values <值>
- 属性列的顺序可与表中的顺序不一致,没有指定属性列默认插入全部
- 值 与 属性列 必须一一对应。
- 没指定的列,自动赋空值
NULL,主码不能为空。
插入子查询结果
将每个系学生的平均年龄插入数据库。
insert into Dept_age (Sdept , Avg_age)
select Sdept AVG (Sage) from Student
group by Sdept;
修改数据¶
修改指定表中满足 where 子句条件的元组
某一元组
将学生 200215121 的年龄改为 22 岁。
多个元组
将所有学生的年龄增加一岁
删除数据¶
删除指定表中满足 where 子句条件的元组
某一元组
删除学号为 200215128 的学生记录
所有元组
视图¶
视图的特点
- 视图是虚表
- 只存放视图的定义,不存放数据
建立视图¶
with check option: 对视图的修改操作,受限更新
删除视图
- 删除指定的视图定义
- 如果该视图上 还导出了其他视图,用
cascade都删除
查询视图,更新视图
当成基本表查询就行。
下图中 IS_S 本身有

视图消解法:转化为对表的查询。
- 进行有效性检查
- 转换成等价的对基本表的查询
- 执行修正后的查询
视图的作用
视图的作用
- 视图能够简化用户的操作视图
- 使用户能以多种角度看待同一数据
- 视图对重构数据库提供了一定程度的逻辑独立性
- 视图能够对机密数据提供安全保护
- 适当的利用视图可以更清晰的表达查询
Last update: April 24, 2026
Discussion